¶ Temporal Difference Learning
Temporal Difference (TD) Learning ist eine Methode aus dem Bereich Reinforcement Learning und beruht darauf, dass eine Schätzung auf Basis einer anderen Schätzung verbessert wird (auch Bootstrapping genannt). Ebenfalls muss nicht - wie z.B. bei der Monte-Carlo-Methode - bis zum Ende einer Episode gewartet werden, damit man entsprechende Änderungen machen kann. Das Lernen findet auch nach jedem Schritt innerhalb einer laufenden Episode statt.[1]
¶ Klassische TD-Methode
Gegeben ist ein Markov-Entscheidungsproblem (siehe Abb. 1) und ein entsprechender Agent, der auf Basis einer Strategie (auch Policy genannt) mit seiner Umgebung interagiert und dessen langfristiges Ziel darin besteht, die Summe der erhaltenen Rewards zu maximieren.
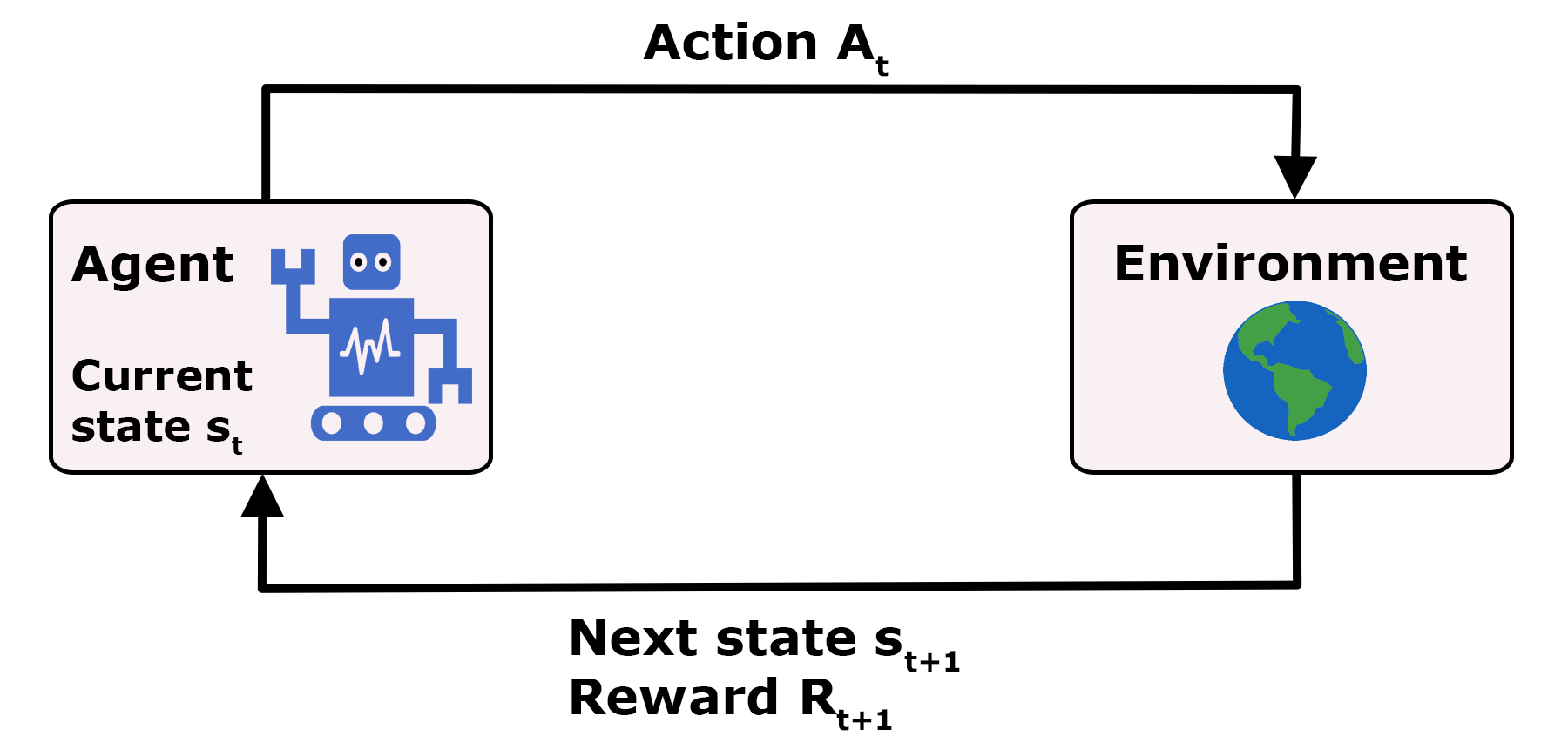
Mithilfe einer Value-Function schätzt der Agent ab, wie viel Reward von einem bestimmten Zustand aus in Zukunft zu erwarten ist. Während des Lernprozesses soll die Funktion schrittweise optimiert werden und daher korrigiert der Agent immer seine Schätzung für den zuletzt besuchten Zustand , nachdem dieser einen bestimmten Reward erhalten hat und in einen neuen Zustand übergegangen ist. Die Anpassung sieht folgendermaßen aus:
Dabei ist die Lernrate (auch Schrittweite genannt) und der Diskontierungsfaktor. Während angibt, wie sehr die ursprüngliche Schätzung angepasst wird, legt hingegen fest, inwiefern zukünftige Rewards gewertet werden. Kleine Werte für machen den Agenten kurzsichtig, weil dieser unmittelbare Rewards (also ) höher priorisiert. Große Werte geben dem Agenten allerdings eine gewisse Weitsichtigkeit, da zukünftige Rewards (also )) stärker gewichtet werden.
Bei der Anpassung werden zwei Schätzungen aus jeweils unterschiedlichen Zeitschritten betrachtet:
- die aktuelle Schätzung
- die als besser empfundene Schätzung (auch TD-Target genannt)
Wie viel Reward in in Zukunft erwartet wird, wird ebenfalls in erwartet. Somit muss auch in inbegriffen sein. Obendrein erhält der Agent beim Übergang von in einen weiteren Reward, nämlich . Dieser muss ebenfalls in enthalten sein und somit gilt das TD-Target als die bessere Schätzung. Die Differenz dieser beiden Werte ist dann der zu korrigierende Fehler in und wird als TD-Error bezeichnet.
Die Ausbreitung dieses Fehlers entlang der besuchten Zustände erfolgt allerdings so kleinschrittig, dass die Value-Function in einem sehr langsamen Tempo gelernt wird.
Auch wird diese Methode TD(0) oder one-step TD genannt.
¶ TD(λ)
TD(λ) ist ein von Sutton entwickelter Algorithmus, der auf der klassischen TD-Methode beruht.[1:1] Üblicherweise wird mit einer Approximation gearbeitet, die mithilfe eines Vektors (auch Weight-Vektor genannt) die wahre Value-Function annähert. Entsprechend wird Im Vergleich zur normalen Methode nicht nur die Schätzung des zuletzt besuchten Zustandes, sondern auch die Schätzungen anderer vergangener Zustände verbessert. Eine zentrale Rolle im Algorithmus spielt dabei der sogenannte Eligibility-Trace , der als eine Art Kurzzeitgedächtnis die jüngsten Aktivitäten bei den Berechnungen der Schätzwerte abspeichert.
¶ Eligibility Trace
Der Eligibility-Trace ist ein Vektor, dessen Anzahl an Einträgen genau der von entspricht und nach jedem Zeitschritt wie folgt aktualisiert wird:
ist die Zerfallsrate und es gilt am Anfang . Anhand von lässt sich feststellen, inwieweit jede Komponenten von in letzter Zeit an Schätzungen beteiligt waren. Ist eine Komponente des Weight-Vektors an der Berechnung der neusten Schätzung beteiligt gewesen, so erhöht sich die dazugehörige Komponente im (durch den Semi-Gradienten mit Bezug auf bestimmt) und zerfällt schrittweise um den Faktor . Große Werte im Eligibility Trace deuten darauf hin, dass die entsprechenden Weights kürzlich oder häufig für die Berechnungen der Schätzwerte verwendet wurden. Sehr kleine Werte drücken aus, dass Komponenten möglicherweise in ganz früheren Berechnungen mitgewirkt haben, jedoch mittlerweile gar nicht oder nur minimal beteiligt sind.
Eine weitere Möglichkeit, den Eligibility Trace zu definieren, sieht folgenderweise aus:[2]
Der oben stehende Ausdruck ist äquivalent zur vorher stehenden Gleichung und veranschaulicht die Gewichtungen aller Schätzungen. Eine zum Zeitpunkt gemachte Schätzung wird mit gewichtet. D.h., Aktivitäten neulich gemachter Schätzungen haben eine größere Wichtigkeit als die der weiter in der Vergangenheit liegenden Schätzungen.
¶ Algorithmus
Wie bei TD(0) wird ebenfalls ein TD-Error berechnet:
In jedem Zeitschritt wird dann der Weight-Vekor angepasst:
Mithilfe von kann jede einzelne Komponente von individuell mit korrigiert werden. Weights, die an vielen oder kürzlich erfolgten Schätzungen beteiligt waren, sind überwiegend verantwortlich für den entstandenen TD-Error und müssen demnach auch stärker angepasst werden. Illustrativ wird mit Abb. 2 die Korrektur vergangener Schätzungen gezeigt, wobei die "Lautstärke" des Fehlers stetig leiser wird, je weiter man in die Zeit zurückgeht.
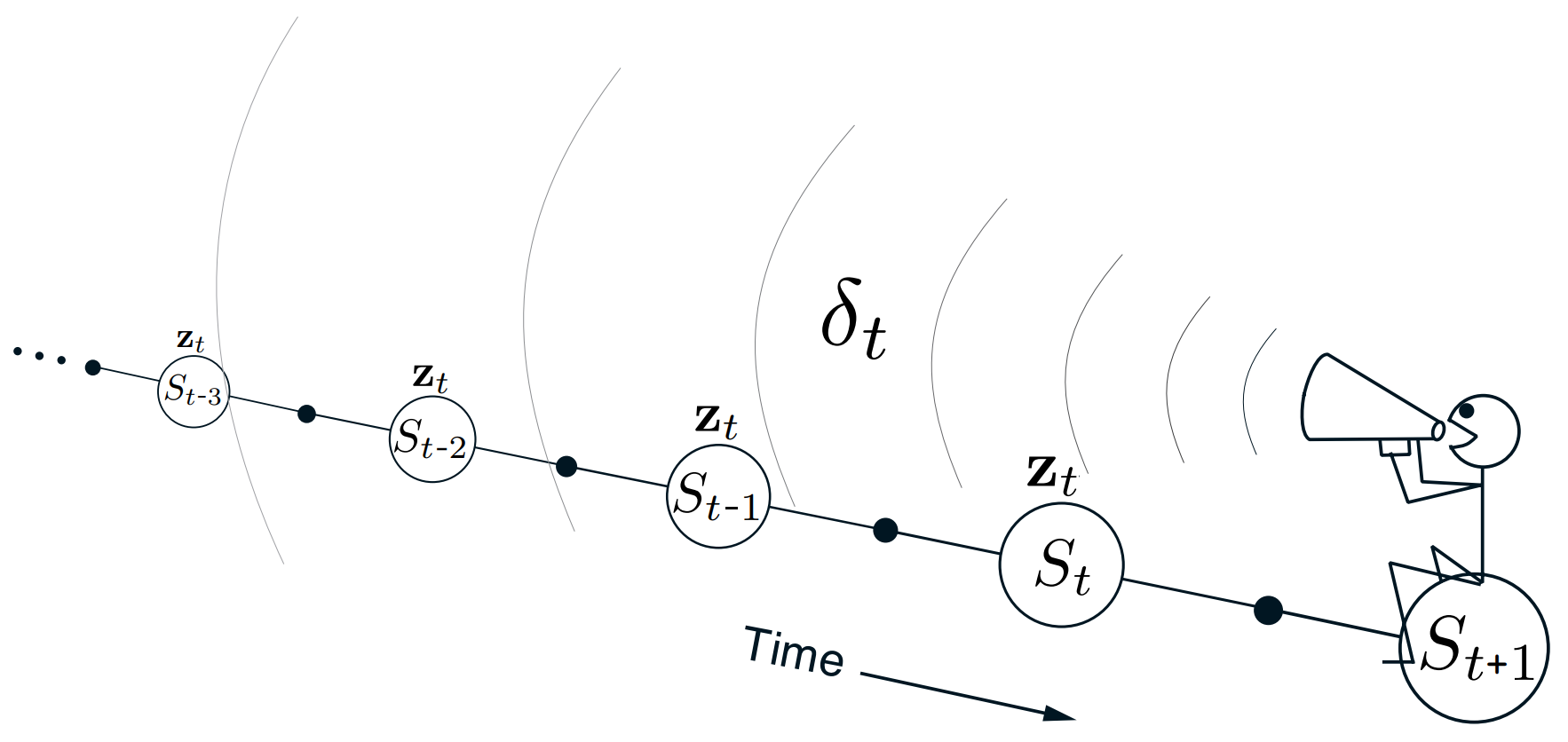
Das Problem, das man hier versucht, zu lösen, nennt sich Temporal Credit Assignment: Vergangene Aktionen erhalten für das am Ende entstandene Ergebnis ihren eigenen "Credit" in Abhängigkeit davon, wie viel sie zum Ergebnis beigetragen haben. Im Falle von TD(λ) ist das Ergebnis der TD-Error, der an andere Schätzungen zurückpropagiert wird. Entscheidend ist dabei der Zerfallsparameter , der die Aufteilung der Credits bestimmt. Ist , so wird nur die letzte Schätzung zur Verantwortung gezogen und diesbezüglich angepasst, was genau dem TD(0) entspricht. Falls gilt, werden alle Schätzungen korrigiert und der Algorithmus verhält sich wie die Monte-Carlo-Methode. Bei Werten zwischen und werden jüngere Schätzungen vom Fehler stärker beeinflusst als ältere.
Das Konzept eines Eligibility-Traces und die Nutzung eines Parameters kann auch auf andere Lernverfahren, wie z.B. Sarsa oder Q-Learning, angewandt werden. Die entsprechenden Algorithmen heißen Sarsa(λ) und Q(λ).
¶ Pseudocode
Sutton und Barto haben den Pseudocode für TD(λ) in ihrem gemeinsamen Buch wie folgt formuliert:[1:2]
Input: the policy π to be evaluated
Input: a differentiable function v: S x R^d → R such that v(terminal,·)=0
Algorithm parameters: step size α > 0, trace decay rate λ ∈ [0,1]
Initialize value-function weights w arbitrarily (e.g., w = 0)
Loop for each episode:
Initialize S
z ← 0
Loop for each step of episode:
Choose A ~ π(·|S)
Take action A, observe R, S'
z ← γλz + ∇v(S,w)
δ ← R + γv(S',w) - v(S,w)
w ← w + αδz
S ← S'
until S' is terminal
¶ Referenzen
¶ Bildquellen
Abb. 1: In Anlehnung an Kumar, A. (2022, 16. Oktober). Reinforcement Learning Real-world examples. https://vitalflux.com/reinforcement-learning-real-world-examples/ (Abgerufen am 17.01.2024)
Abb. 2: Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press. pdf