¶ Amazons
Amazons (oder auch The Game of Amazons) ist ein strategisches Brettspiel für zwei Spieler, erfunden von Walter Zamkauskas im Jahr 1988. Da das Spiel territorialer Natur ist, wird das Spiel entfernter als eine Mischung aus den Spielen Schach und Go angesehen.
¶ Regeln

Gespielt wird auf einem 10×10-Brett. Die Spieler haben jeweils 4 Amazonen einer Farbe; Weiß oder Schwarz und werden wie in Abbildung 1 auf das Brett platziert.
Die Spieler ziehen abwechselnd und Weiß beginnt.
Ein Zug besteht aus zwei Teilen:
- Eine eigene Amazone wird auf ein leeres Feld in orthogonaler oder diagonaler Richtung gezogen und darf dabei keine andere Amazone oder Pfeil überqueren.
- Die gezogene Amazone verschießt vom Endpunkt des Zuges aus einen Pfeil auf ein leeres Feld, ebenfalls in orthogonaler oder diagonaler Richtung, ohne das Überqueren einer Amazone oder eines anderen Pfeils.
¶ Pfeil
Der geschossene Pfeil einer Amazone bleibt bis zum Spielende auf dem Feld und dient als eine Blockade des Feldes.
¶ Spielende
Es besteht eine Zugpflicht: Der Spieler, der am Zug ist, muss eine Amazone ziehen und einen Pfeil verschießen.
Der Spieler, der als Erster nicht mehr eine Amazone ziehen kann, hat verloren.
¶ Strategie

Die Strategie des Spiels besteht darin, mithilfe eigener Amazonen und des Verschießens von Pfeilen die Mobilität der gegnerischen Amazonen so einzuschränken, dass große Gebiete für sie unerreichbar werden. Die eigenen Amazonen werden im besten Fall in diesen großen Gebieten platziert.
Mit jedem Zug wird die verfügbare Spielfläche verkleinert, sodass am Ende nur noch Gebiete verbleiben. Bis zum Ende des Spiels bewegen sich die Amazonen dann ausschließlich in diesen Territorien und verschießen Pfeile, bis sie dies nicht mehr können. Die Erlangung von Territorium ist offensichtlich ein wichtiger Aspekt des Spiels, da der Spieler mit dem meisten Territorium in der Lage sein sollte, den letzten Zug zu machen und das Spiel zu gewinnen.
¶ Komplexität
Robert Hearn[1] begründet die Komplexität in seinem Paper "Amazons is PSPACE-complete" wie folgt:
"Das Spiel Amazons ist als PSPACE-vollständig klassifiziert und weist eine enge Verbindung zu einem anderen Problem namens "Formula Game" auf. Im Formula Game wählt jeder Spieler nacheinander Variablen aus einer gegebenen positiven, konjunktiven Normalform (CNF)-Formel aus. Spieler eins gewinnt, wenn die Formel wahr ist, basierend auf den ausgewählten Werten der Variablen. Schaefer hat gezeigt, dass die Entscheidung, wer das Formula Game gewinnt, PSPACE-vollständig ist.
Die PSPACE-vollständige Reduktion konstruiert eine spezielle Amazons-Konfiguration, die die Spieler zwingt, das Formula Game effektiv zu spielen. Jede Variable in der Formel wird durch spezielle Logik- und Verkabelungsgadgets repräsentiert. Je nachdem, welcher Spieler zuerst in einer Variable spielt, wird ein Signal entweder aktiviert oder blockiert. Durch geschickte Manipulation der Amazonen-Züge können die Spieler spezifische Signale erzeugen, die schließlich nur dann aktiviert werden, wenn die ursprüngliche Formel wahr ist."
¶ Base Wiring
Signale breiten sich entlang von Drähten aus. Die Strukur eines solchen Drahtes wird in Abbildung 3(a) gezeigt. Die Amazone A kann sich um einen Platz nach unten bewegen und nach unten schießen, was der Amazone B ermöglicht, sich ebenfalls um einen Platz nach unten zu bewegen und nach unten zu schießen; C kann nun dasselbe tun. Wenn also das Bewegen einer Amazone dazu führt, dass eine andere sich bewegen kann und möglicherweise sich eine weitere dadurch bewegen kann, wird dies die grundlegende Methode der Signalpropagation genannt.
Eine Amazone, die sich rückwärts bewegt (in Richtung Eingang, weg von der Ausgangsrichtung) und rückwärts schießt, bedeutet, dass sie sich zurückgezogen hat.
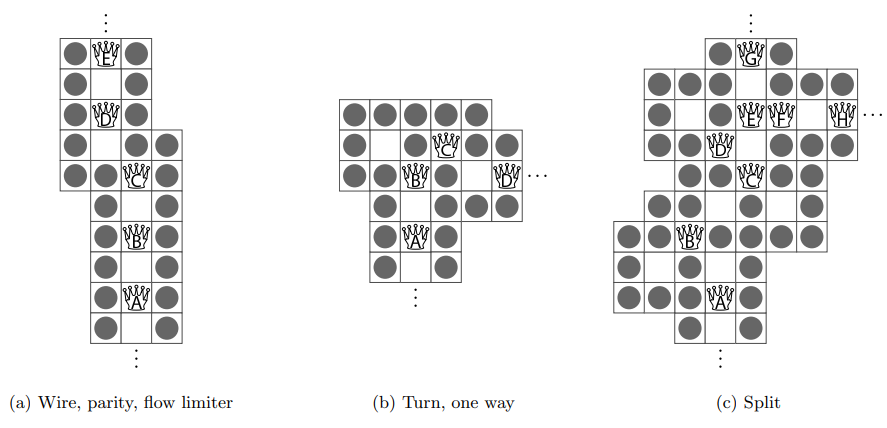
Abbildung 3(a): Wenn also nun A, B und C sich um ein Feld nach unten bewegt haben und nach unten geschossen haben, kann D folgen und E freigeben. Dadurch wurde die Position des Drahtes um eins nach rechts in horizontaler Richtung verschoben. Danach können sich D und E nur um einen Platz zurückziehen, weil D gezwungen ist, in den von C freigegebenen Raum zu schießen.
Das Bewegen um Ecken wird in Abbildung 3(b) gezeigt. Wenn A sich zurückzieht, kann B folgen, dann C und nach oben links schießen; dann kann sich D zurückziehen. Dieses Gadget ermöglicht nur einseitigen Signalfluss. Angenommen, D hat sich nach rechts bewegt und geschossen. Dann kann C nach unten und rechts ziehen und nach rechts schießen. B kann dann nach oben rechts ziehen, aber es kann nur in das Feld schießen, das es gerade verlassen hat. Daher kann A nicht nach oben ziehen und schießen.
Das Split-Gadget in Abbildung 3(c) zeigt das Aufteilen eines Signals. A ist der Eingang; G und H sind die Ausgänge.
Bei einem Split-Gadget können sich die Amazonen G und H zurückziehen, wenn sich A zurückziehen kann:
Bis A sich zurückzieht, können keine nützlichen Züge gemacht werden, weil C, D und F sich nicht bewegen dürfen, ohne zurück in das Feld zu schießen, das sie verlassen haben. A, B und E können sich um eine Einheit bewegen und zwei schießen, aber das führt zu nichts.
Aber wenn A sich zurückzieht, kann B nach unten rechts ziehen und nach unten schießen; C nach unten links zwei ziehen, nach unten links schießen; D nach oben links ziehen, nach unten rechts drei schießen; E nach unten zwei ziehen, nach unten links schießen; F nach unten links ziehen, nach links schießen. Dies schafft Platz für G und H, sich zurückzuziehen[1:1].
¶ Logic gadgets
Das Variable-Gadget ist in Abbildung 4(a) dargestellt. Wenn Weiß zuerst in einer Variable zieht, kann er A nach unten bewegen und unten schießen, was B ermöglicht, sich später zurückzuziehen und Schwarz eine festgesetzte Amazone hat. Wenn Schwarz zuerst zieht, kann er nach oben ziehen und nach oben schießen, was B daran hindert, sich überhaupt zurückzuziehen.
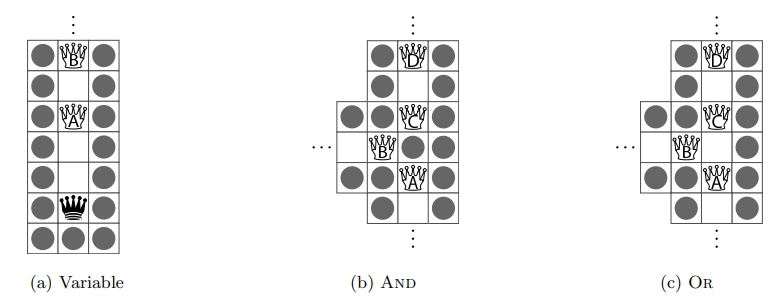
Die And- und Or-Gadgets sind in den Abbildungen 4(b) und 4(c) dargestellt. In beiden ist A und B die Eingabe, und D ist die Ausgabe.
In einem And-Gadget kann sich die Amazone D zurückziehen, wenn und nur wenn A und B sich zuerst zurückziehen, denn es kann keine Amazone nützlich ziehen, bis mindestens eine der Eingaben sich zurückgezogen hat. Wenn B sich zurückzieht, wird zwar Platz freigegeben, aber C kann sich dort nicht zurückziehen; ähnlich, wenn nur A sich zurückzieht. Aber wenn sich beide Eingaben zurückziehen, kann sich C nach unten links bewegen, nach unten rechts schießen und so D ermöglichen, sich zurückzuziehen.
In einem Or-Gadget kann sich die Amazone D zurückziehen, wenn entweder A oder B sich zuerst zurückzieht.
Hier ähnliches Prinzip wie bei dem And-Gadget[1:2].
¶ Crossover gadgets
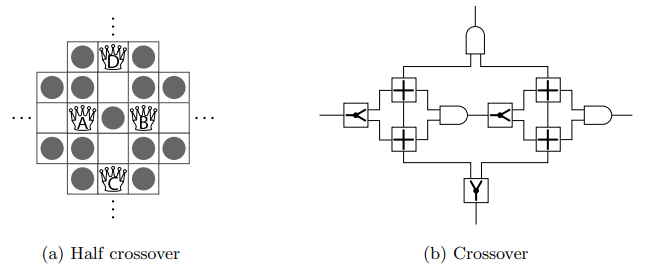
Durch die Verwendung von "Half crossover"-Gadgets (Abb. 5(a)), Splits und Ands können wir ein vollständiges Crossover-Gadget herstellen, das schematisch in Abbildung 5(b) dargestellt ist. (Splits werden mit einem ![]() , "Half crossover" mit einem
, "Half crossover" mit einem ![]() und Ands mit einem
und Ands mit einem ![]() dargestellt.)
dargestellt.)
In einem "Half Crossover"-Gadget entspricht die Anzahl der zurückziehenden Ausgabe-Amazonen B und D der Anzahl der Eingabe-Amazonen A und C, die sich bereits zurückgezogen haben, wobei dies 0, 1 oder 2 sein kann. Jegliche Kombination dieser Rückzüge ist möglich.
Wenn keine Eingaben zurückgezogen wurden, gibt es keine Züge, die es den Ausgaben ermöglichen, sich zurückzuziehen. Im Falle eines Rückzugs von A kann entweder B oder D, jedoch nicht beide, sich um einen Platz unter D bewegen und nach unten links schießen. Eine ähnliche Überlegung gilt, wenn C sich zurückzieht. Wenn sich beide Eingaben zurückziehen, besteht die Möglichkeit für beide Ausgaben, sich zurückzuziehen.
In einem Crossover-Gadget kann sich die Ausgabe-Amazone der rechten AND-Operation zurückziehen, wenn sich die Eingabe-Amazone der linken Split-Operation zurückzieht. Gleiches gilt für die Ausgabe-Amazone der oberen AND-Operation in Bezug auf die Eingabe-Amazone der unteren Split-Operation. Wenn sich eine Eingabe zurückzieht, kann die entsprechende Ausgabe zurücktreten. Bei Rückzug beider Eingaben ermöglicht die Aktivierung beider "Half Crossover"-Ausgaben beiden Crossover-Ausgaben, sich zurückzuziehen. Falls die Eingabe für die linke Split-Operation sich nicht zurückgezogen hat, kann höchstens eine Eingabe für die linke AND-Operation zurückgezogen werden. Somit ist der Rückzug der Ausgabe-Amazone der linken AND-Operation ausgeschlossen. Analog dazu gilt, dass, wenn sich die Eingabe für die untere Split-Operation nicht zurückgezogen hat, auch die Ausgabe der oberen AND-Operation nicht zurückziehen kann[1:3].
¶ Victory gadget
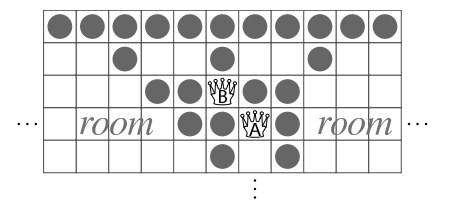
Das And-Gadget wird durch die Wahrheitswerte der Variablen in der Formel beeinflusst. Wenn die Formel wahr ist, wird das And-Gadget aktiviert und das aktivierende Signal wird anschließend in ein Victory-Gadget (wie in Abbildung 6 gezeigt) eingeführt, das zwei Räume hat. Falls das And-Gadget also aktiviert wird, kann Weiß beide Räume für sich beanspruchen. Somit hat Weiß das Spiel gewonnen. Falls das And-Gadget nicht aktiviert wurde, kann Weiß nur einen der Räume beanspruchen und würde in diesem Fall verlieren.
In einem Victory-Gadget kann Spieler Weiß nur dann beide Räume erreichen, wenn sich A zurückziehen kann. Denn wenn sich B bewegt, bevor A sich zurückgezogen hat, muss B auf das zuvor verlassene Feld schießen, was den Zugang zu einem der beiden Räume blockiert.
Wenn jedoch A sich zuerst zurückzieht, kann B in das obere linke Feld und einen Pfeil nach unten rechts auf die Ursprungsposition von A schießen. Dadurch bleibt der Weg zu dem rechten Raum frei und der linke kann beansprucht werden. Im späteren Verlauf wird der linke Raum verlassen und der rechte kann beansprucht werden[1:4].
¶ PSPACE-completeness
Eine positive CNF-Formel wird in eine entsprechende Amazons-Position umgewandelt. Die Umwandlung erfolgt in polynomialer Zeit: Für eine CNF-Formel mit Variablen und Klauseln werden höchstens Crossover-Gadgets benötigt, um jede Variable mit jeder Klausel zu verbinden. Die Spieler wählen abwechselnd Variablen dieser Formel und wenn alle Variablen gewählt wurden, kann der weiße Spieler nur die Drähte von den von ihm gewählten Variablen aktivieren. Diese Zuordnung der wahren Variablen entspricht den Wahrheitswerten der zugrunde liegenden Formel . Falls dann die Formel keine verneinten Variablen enthält, kann der Weiß beide Räume des Victory-Gadget erreichen, wenn die Formel unter der Variablenzuordnung wahr ist.
Folglich kann ein Spieler das Amazons-Spiel gewinnen, wenn und nur wenn er auch das entsprechende Formelspiel gewinnen kann und daher ist das Spiel Amazons PSPACE-schwer.
Da das Spiel nach einer polynomialen Anzahl von Zügen endet, kann durch eine Suche aller möglichen Zugsequenzen in polynomialer Zeit der Gewinner bestimmt werden. Daher gehört Amazons zu PSPACE[1:5].
¶ Lösungsansätze
"Bisher verwenden die meisten starken Amazons-Programme traditionelle Minimax-basierte Algorithmen."[2] INVADER und AMAZONG sind solch besagte Programme. Jedoch haben sich Monte-Carlo-basierte Algorithmen in der Go-Programmierung als äußerst wirksam erwiesen[3][4]. Aufgrund der gemeinsamen Eigenschaften von Go und Amazons, nämlich einem hohen Branchingfaktor und der territorialen Natur, liegt die Vermutung nahe, dass die Wirksamkeit auch auf Amazons übertragbar ist. Im Folgenden wird der Monte-Carlo-Ansatz (in Form eines Programms namens INVADERMC) und die damit verbundenen Verbesserungen von Robert J. Lorentz[2:1] näher erläutert.
¶ INVADERMC
Das Programm INVADER mit einem implementierten Monte-Carlo-Algorithmus wird auch INVADERMC genannt.
¶ Monte-Carlo-Tree-Search
Der hier gezeigte Lösungsansatz beinhaltet den Monte-Carlo-Tree-Search mit einigen Anpassungen und Verbesserungen.
¶ Monte-Carlo-Search Verbesserungen
¶ UCT
UCT (Upper Confidence Bounds applied to Trees) ersetzt die Liste der Kandidatenzüge (die durch den Monte-Carlo-Search erhaltenen) durch einen Suchbaum (UCT-Baum). Jeder Knoten im UCT-Baum verfolgt den Gewinnsatz einer Position. Vom Wurzelknoten wird ein Pfad zu den Blattknoten mit dem höchsten Expansionswert gewählt.
Eine zufällige Simulation beginnt am Blattknoten und kann dessen Kinderknoten zum UCT-Baum hinzufügen. Die Entscheidung zur Erweiterung eines Blattknotens basiert auf der Anzahl der Besuche dieses Knotens. Der Expansionswert eines Knotens besteht aus dem Gewinnprozentsatz aller Simulationen, die durch ihn gegangen sind, plus einem Bias-Wert. Dieser Bias-Wert ermöglicht weniger besuchten Knoten, ebenfalls an Simulationen teilzunehmen.
Berechnung des Expansionswertes:
- : Anzahl der Simulationen, die durch den Elternknoten des betrachteten Knoten gegangen sind
- : Anzahl der Simulationen, die durch den betrachteten Knoten gegangen sind
- : Konstante; kleiner Wert für bedeutet, dass gut performende Züge mit hoher Wahrscheinlichkeit weiterhin häufig erkundet werden (Exploitation); großer Wert für bedeutet, dass auf jeder Ebene mehr Züge ausprobiert werden (Exploration)
Es ist also wichtig, die Exploitation/Exploration-Konstante richtig zu wählen.
Nach Robert J. Lorentz[2:2] sollte für den INVADERMC auf gesetzt werden, um eine maximale Tiefe von 8 des UCT-Baums zu erreichen (durch eine Limitation der Zeit auf 30 Minuten pro Spiel auf Turnieren).
Wie oben bereits schon erwähnt hängt die Entscheidung, ob ein Blattknoten erweitert werden soll oder nicht, davon ab, wie oft dieser Knoten besucht wurde. Ein Blattknoten direkt zu erweitern würde nur Zeit kosten, diese zu evaluieren und den UCT-Baum sehr schnell wachsen lassen. Demnach wurde festgestellt, dass ein Knoten nicht erweitert werden sollte, solange er nicht um die 40 Mal besucht wurde[2:3].
¶ Frühzeitige Beenden der MC-Simulation
Es ist entscheidend, den optimalen Zeitpunkt für das Beenden der Monte-Carlo-Simulation festzulegen, um Ressourcen wie Zeit und Rechenkapazität zu sparen. Im Allgemeinen wird eine Simulation beendet, wenn ein Spieler keine legalen Züge mehr hat und somit verliert. In INVADERMC endet die Simulation jedoch früher: Sobald alle Amazonen eines Spielers vollständig von den feindlichen Amazonen isoliert sind. Obwohl dies eine präzisere und frühzeitige Bewertung eines Spielvorteils ermöglicht, erfordert es, dass diese Bedingung während der Simulation überwacht wird, was zu einer Verlangsamung führen kann[2:4].
¶ Evaluation Function
Der Sinn einer zufälligen Simulation besteht darin, statistische Belege für die Stärke eines Zuges zu liefern. Mithilfe der Evaluierungsfunktion lässt sich früher entscheiden, ob eine Simulation eher zu einer Gewinn- oder Verlustposition führt. Dabei wird die Evaluierungsfunktion jedes Mal nach einer bestimmten Anzahl (6 Züge nach Robert J. Lorentz[2:5]) gespielter Züge aufgerufen.
Die Faktoren für die Bewertung einer Position sind:
- Mobility Evaluation
- Territory Evalaution
Mobility und Territory Evaluation werden im folgenden näher beschrieben durch Hikari Kato[5].
¶ Mobility Evaluation
In Amazons ist es von Vorteil, mehr legale Züge in seinem Zug zur Verfügung zu haben als der Gegenspieler. Folglich wird eine Position, in der die Anzahl der legalen Züge gering ist, als nachteilig betrachtet.
"Die Mobility Evaluation (ME) einer Position ist der Wert, der sich ergibt, wenn man die Anzahl der legalen Züge des aktuellen Spielers in einem bestimmten Spielzustand subtrahiert."[5:1]
Beispiel: SpielerWeiß hat 161 legale Züge und SpielerSchwarz hat 166 legale Züge. Dann ist die ME in der Position aus Sicht vom SpielerWeiß:
¶ Territory Evaluation
Das Konzept des Territoriums spielt in Amazon eine sehr wichtige Rolle. Das Territorium eines Spielers umfasst Felder, die nur von den Amazonen dieses Spielers erreicht werden können. Je mehr ein Spieler Zugang zu leeren Feldern hat, desto größer ist der Vorteil, da das Spielfeld im Endspiel in getrennte Gebiete/Territorien aufgeteilt wird[5:2].
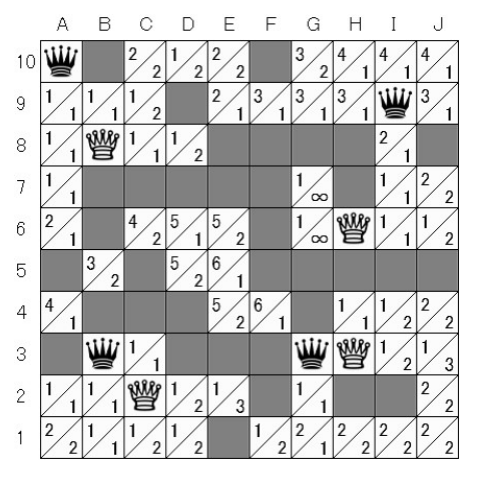
Abbildung 7 zeigt die minimale Anzahl von Zügen, die erforderlich sind, um jedes Feld auf dem Spielbrett mit den Amazonen der Spieler zu erreichen. Der Wert in der oberen linken Ecke stellt die erforderliche Zuganzahl für den SpielerWeiß dar, währenddessen die untere rechte Ecke die des SpielerSchwarz repräsentiert.
Zum Beispiel benötigt der SpielerWeiß, um das Feld C6 zu erreichen, mindestens vier Züge.
Im Gegensatz dazu benötigt SpielerSchwarz nur 2 Züge:
Zufolge der Territory Evaluation gehört das Feld C6 zum Territorium von SpielerSchwarz.
stellt die minimal benötigte Anzahl der Züge für den Spieler zum Feld dar. Dem Beispiel oben zufolge wären und .
So wird die geringste Anzahl von Zügen bestimmt, die jeder Spieler benötigt, um jede leere Zelle auf dem Spielfeld zu erreichen. Die Summe dieser Werte über alle leeren Zellen ermöglicht eine Bewertung der Spielposition, basierend auf den eingenommenen Territorien.
Die Territoriumsbewertung einer Position für SpielerWeiß wird wie folgt definiert:
wobei
Falls beide Spieler ein Feld in der gleichen Anzahl von Zügen erreichen können, besteht die Möglichkeit, den Bewertungswert beliebig festzulegen[5:3]. In diesem Fall wurde er jedoch gemäß Lieberum, J.[6], auf festgelegt.
hat den Wert:
- 0, wenn das Feld von keinem Spieler erreichbar ist
- , wenn das Feld von beiden Spielern mit gleicher Zuganzahl erreichbar ist
- 1, wenn das Feld vom SpielerWeiß mit geringerer Zuganzahl erreichbar ist
- -1, wenn das Feld vom SpielerSchwarz mit geringerer Zuganzahl erreichbar ist
¶ Forward Pruning
Eine zweite Verwendung für die Evaluierungsfunktion ist das (unsichere) Forward Pruning.
Anstatt Zeit und Platz zu verschwenden, um den UCT-Baum für alle legalen Züge zu erstellen, kann die Evaluierungsfunktion benutzt werden, um die zum Beispiel Top-400 Züge (so in INVADERMC) auszuwählen, die am wahrscheinlichsten gut sind.
Es werden bevorzugt Informationen von vielversprechenden Zügen gesammelt, jedoch werden auch gelegentlich vermeintliche schwächere Züge erfasst, um ihnen eine Chance zu geben, sich zu beweisen[2:6].
¶ Tiefe-1 UCT-Suche
Für die ausgewählten vielversprechenden Züge wird eine Tiefe-1 UCT-Suche durchgeführt. Die Idee hinter der Tiefe-1 UCT-Suche ist es, die Qualität der Züge auf einer begrenzten Tiefe (hier Tiefe 1) zu bewerten, ohne den gesamten Suchbaum weiter zu durchsuchen. Dies ermöglicht eine effiziente Identifizierung vielversprechender Züge, ohne die Rechenressourcen zu stark zu belasten. Die UCT-Bias-Werte werden verwendet, um zu entscheiden, welcher Zug simuliert werden soll. Diese Werte helfen dabei, den Trade-off zwischen Exploration und Exploitation zu steuern und die vielversprechendsten Züge zu priorisieren.
¶ Evaluation Parity Effect
Der Evaluation Parity Effect bezieht sich auf eine beobachtete Schwankung in den Bewertungswerten während der Simulationen im Monte-Carlo-Tree-Search (MCTS)-Ansatz von Richard J. Lorentz. Dieser Effekt tritt aufgrund der festgelegten Anzahl von zufälligen Zügen auf, die vor dem Aufruf der Evaluierungsfunktion durchgeführt werden - üblicherweise 6 Züge in diesem speziellen Ansatz.
Da die Simulationen von jedem Blattknoten im UCT-Baum beginnen können und je nach Position im Baum entweder mit Weiß oder Schwarz am Zug enden können, resultiert der Parity Effect in Schwankungen der Bewertungswerte. Diese Schwankungen hängen davon ab, welcher Spieler am Ende der Simulation die letzten Züge durchführt.
Die Lösung für dieses Problem besteht darin, alle zufälligen Simulationen mit dem gleichen Spieler am Zug zu beenden. Durch diese Anpassung wird sichergestellt, dass die Simulationen konsistente Ergebnisse liefern, unabhängig davon, an welchem Punkt im Baum die Simulation gestartet wurde. Wenn beispielsweise eine 6-Zug-Simulation durchgeführt wird, kann dies zu einer 6- oder 5-Zug-Simulation führen, abhängig davon, wo sich der aktuelle Zustand im Baum im Vergleich zur Startposition befindet.
Die Anpassung des Spielerwechsels in den Simulationen hilft, die Varianz der Bewertungswerte zu reduzieren und sorgt für eine konsistentere Einschätzung der Positionen im Spielbaum. Dies trägt dazu bei, dass die Monte Carlo Tree Search genauer und zuverlässiger arbeitet[2:7].
¶ Progressive Widening
Diese Technik unterstützt den UCT-Algorithmus, indem sie zunächst nur die vielversprechendsten Kinder eines Knotens in Betracht zieht und allmählich weitere Kinder hinzufügt, bis schließlich alle Kinder des Knotens vom Algorithmus berücksichtigt werden.
Die Grundidee besteht darin, die Erkundung von Kinderknoten schrittweise zu erhöhen, abhängig davon, wie oft der übergeordnete Knoten besucht wurde. Wenn ein Knoten selten besucht wurde, werden nur einige seiner Kinder betrachtet. Mit zunehmender Besucheranzahl werden nach und nach mehr Kinder hinzugefügt, bis alle möglichen Kinder berücksichtigt werden, wenn der übergeordnete Knoten ausreichend oft besucht wurde.
Als Beispiel erstellt INVADERMC einen UCT-Baum mit insgesamt 1500 Knoten (unter normalen Zeitbedingungen). Bis ein spezifischer Knoten 1000 Mal besucht wurde, werden nur 5 seiner Kinder in Betracht gezogen. Alle 1000 Besuche werden dann zusätzlich weitere 5 Kinder des Knotens in die Betrachtung einbezogen (nach Richard J. Lorentz[2:8]).
¶ Minor Tuning (bei Zeitlimitationen)
In vielen Spielen, darunter auch Amazons, ist ein guter Start wichtig. Daher benötigen viele Programme, insbesondere solche, die auf Monte-Carlo-Methoden basieren, mehr Zeit für die Züge in den frühen Phasen des Spiels.
INVADERMC implementiert dies auf einfache, aber dennoch nützliche Weise. Abhängig von der verfügbaren Zeit pro Zug wird das Basiszeitlimit für die ersten 10 Züge verdreifacht, für die nächsten 10 verdoppelt, für die nächsten 10 um 1,5 erhöht, für die nächsten 10 bleibt es beim Basislimit und die verbleibende Zeit wird auf die restlichen Züge aufgeteilt.
Aufgrund der begrenzten Zeit für die letzten Züge verwendet das Programm in diesem Stadium seinen grundlegenden Minimax-Algorithmus anstelle des UCT-Algorithmus, da Letzterem oft die Zeit fehlt, um einen ausreichend großen Baum für einen guten Zug zu erstellen[2:9].
¶ Resultate
Die Einführung des Monte-Carlo mit dem UCT-Ansatz in das Amazons-Programm INVADER führt zur Entwicklung von INVADERMC, das signifikant stärker ist und INVADER in 80% der Spiele besiegt. INVADERMC verwendet keine reine UCT-Methode, sondern prunet (auf unsichere Weise) Kindknoten und führt zufällige Spiele nur für etwa 6 Züge durch. Die Anwendung von "Progressive Widening" und die Anpassung von UCT-Tiefe und Knotenbesuchen pro Blattexpansion sind übliche Praktiken bei der Verwendung von UCT.
Dadurch konnten folgende Resultate erzielt werden[2:10]:
| Programm 1 | Programm 2 | Prozentsatz der gewonnenen Spiele von Programm 1 gegen Programm 2 |
|---|---|---|
| Pures Monte-Carlo | INVADER | 15% |
| Monte-Carlo mit Eval. Function und Forward Pruning | INVADER | 40% |
| Monte-Carlo mit UCT | INVADER | 60% |
| Monte-Carlo mit UCT und allen Verbesserungen* | INVADER | 80% |
| Monte-Carlo mit UCT und allen Verbesserungen außer Progressive Widening | INVADER | 70% |
| Monte-Carlo mit UCT und allen Verbesserungen außer Parity Effect Adjustment | INVADER | 73% |
*Folgende Verbesserungen sind gemeint: Frühzeitige Beenden der Simulation, Evaluation Function, Forward Pruning, (Evaluation) Parity Effect Adjustment, Progressive Widening, Minor Tuning
Diese Ergebnisse basieren auf mindestens 100 Spielen und einer Zeitvorgabe von 30 Minuten pro Spieler. Mit welchen jeweiligen Verbesserungen das erste Programm gegenüber dem zweiten Programm erzielen konnte, wird in der dritten Spalte gezeigt. Die letzten beiden Zeileneinträge zeigen die Auswirkung des Wegfalls einer der späteren Erweiterungen[2:11].
Zu sehen ist, dass der Monte-Carlo-Search-Ansatz alleine nicht ausreicht, um das Mini-max-basierte Programm INVADER zu schlagen. Dieser weiste noch zu viele Fehlentscheidungen auf und berücksichtigte kaum langfristige Konsequenzen. Die Kombination einer Bewertungsfunktion und des (unsicheren) Forward Pruning für das Auswählen der besten Züge und sich auf diese zu beschränken konnte Zeit sparen und mehr Simulationen durchführen, was zu einem Anstieg auf 40% gegenüber dem INVADER führte. Eine signifikante Verbesserung, das UCT, erlaubte nun das Problem, welches dem purem Monte-Carlo-Search zugrunde lag, zu lösen und somit konnten langfristige Konsequenzen auch berücksichtigt werden.
Die schlussendlich letzte Kombination des Monte-Carlo-Search mit UCT und den restlichen Verbesserungen (Frühzeitige Beenden der Simulation, Evaluation Function, Forward Pruning, (Evaluation) Parity Effect Adjustment, Progressive Widening, Minor Tuning) siegte in 80% der Spiele gegen INVADER.
Der UCT-Algorithmus verbessert die Auswahl der Züge, indem ein Suchbaum erstellt wird, der den Gewinnsatz einer Position verfolgt. Die Einstellung der Exploitation/Exploration-Konstanten auf und die Begrenzung der Tiefe des UCT-Baums auf 8 tragen zu einer effizienten Suche bei.
Das vorzeitige Beenden der Simulation, sobald alle Amazonen eines Spielers von feindlichen Amazonen isoliert sind, ermöglicht eine präzise Bewertung des Spielvorteils und spart Ressourcen.
Die Evaluierungsfunktion berücksichtigt die Mobility Evaluation und Territory Evaluation. Die Mobility Evaluation betrachtet die Anzahl der legalen Züge, während die Territory Evaluation die Zugänglichkeit zu leeren Feldern berücksichtigt.
Die Evaluierungsfunktion wird auch für das Forward Pruning verwendet, um die vielversprechendsten Züge auszuwählen (mithilfe einer Tiefe-1 UCT-Suche).
Die Anpassung des Spielerwechsels in den Simulationen reduziert die Varianz der Bewertungswerte und sorgt für konsistente Ergebnisse.
Progressive Widening trägt dazu bei, den UCT-Algorithmus zu unterstützen, indem zunächst nur die vielversprechendsten Kinder eines Knotens betrachtet werden.
Bei einer bestehenden Zeitlimitation ermöglicht das Minor Tuning die Anpassung der Zeitlimits für die ersten Züge und dadurch eine gezielte Ressourcenverwendung in den frühen Phasen des Spiels.
¶ Referenzen
¶ Bildquellen
Abb. 1 Anfangsstellung: ludii.games
Abb. 2 Spielende: ludii.games
Abb. 3 Wiring gadgets: pdf
Abb. 4 Logic gadgets: pdf
Abb. 5 Crossover gadgets: pdf
Abb. 6 Victory gadget: pdf
Abb. 7 Beispielposition für Territory Evaluation: Springer Link
¶ Literaturverzeichnis
HEARN, Robert A. Amazons is PSPACE-complete. arXiv preprint cs/0502013, 2005. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
LORENTZ, Richard J. Amazons discover monte-carlo. In: International Conference on Computers and Games. Springer Berlin Heidelberg, 2008. S. 13-24. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Coulom, R.: Efficient selectivity and back-up operators in Monte-Carlo Tree Search. In:
van den Herik, H.J., Ciancarini, P., Donkers, H.H.L.M(J.) (eds.) CG 2006. LNCS,
vol. 4630. Springer, Heidelberg (2007) ↩︎Gelly, S., Wang, Y., Munos, R., Teytaud, O.: Modification of UCT for Monte-Carlo Go.
Technical Report 6062, INRIA (2006) ↩︎KATO, Hikari, et al. Comparative study of monte-carlo tree search and alpha-beta pruning in amazons. In: Information and Communication Technology: Third IFIP TC 5/8 International Conference, ICT-EurAsia 2015, and 9th IFIP WG 8.9 Working Conference, CONFENIS 2015, Held as Part of WCC 2015, Daejeon, Korea, October 4-7, 2015, Proceedings 3. Springer International Publishing, 2015. S. 139-148. ↩︎ ↩︎ ↩︎ ↩︎
Lieberum, J.: An evaluation function for the game of Amazons. Theoretical Computer Science Vol 349, pp. 230–244, (2005) ↩︎