¶ Einführung

Ms. Pac-Man stellt eine Weiterentwicklung des ursprünglichen Pac-Man-Spiels dar, das im Jahr 1982 von der Firma Midway Manufacturing veröffentlicht wurde[1]. Das Spiel ist der Kategorie der Arcade-Spiele zuzuordnen und dabei handelt es sich eine weibliche Spiel-Charekter. Anders als in Pac-Man bewegen sich die Geister in Ms. Pac-Man zufällig und viele Details wie Bewegungsmechaniken oder Verhaltensregeln bleiben verborgen. Aufgrund seiner klar definierten Spielregeln, der hohen Komplexität sowie der Möglichkeit zur Evaluation von Entscheidungsstrategien eignet sich Ms. Pac-Man hervorragend für den Einsatz in der Erforschung künstlicher Intelligenz und wird daher regelmäßig im Rahmen von KI-Wettbewerben verwendet[2].
¶ Pac-Man
Das Spiel, vom dem Ms. Pac-Man ins Leben gerufen wurde, wurde im Jahr 1980 in Japan von Toru Iwatani entwickelt und von der Firma "Namco" unter dem Namen "Puckman" als Arcade-Spiel veröffentlicht, der allerding für den amerikanischen Markt in "Pac-Man" umbenannt wurde[3]. Der Grund zur einen Umbennenung solle daran liegen, dass die Menschen über den Name lustig machen könnten, indem sie Puckman als Fuckman bezeichnen würden. Nach dem Erfolg des Spiel wurden unterschiedliche Versionen wie Ms. und Baby Pac-Man entwickelt. Insbesondere Ms. Pac-Man erwies sich aufgrund des Zusammenspiels von einfacher Spielmechanik und subtiler Komplexität als ein wertvolles Instrument für die wissenschaftliche Forschung.
¶ Spielkonzept von Ms. Pac.Man
Das Spielprinzip von Ms. Pac-Man ähnelt dem von Pac-Man. Der Charakter bewegt sich durch Tunnel, sammelt Punkte und versucht, den Geistern auszuweichen. Gleichzeitig bewegen sich die Geister in Richtung der Ms. Pac-Man mit dem Ziel, diese zu fangen, was zum Verlust der Runde führt. Zusätzlich gibt es sogenannte Kraftpillen (wie großer Punkt in Abb. 6), die die Geister in blaue, essbare Gegner verwandeln (siehe in Abb. 1 und Abb. 2). Dies ermöglicht Ms. Pac-Man, die blauen Geister zu fressen und dadurch eine höhere Punktzahl zu erzielen. Die gefressenen Geister werden daraufhin deaktiviert und zu ihrem Startpunkt mit der Darstellung von Augen (Siehe Abb.2) zurückgeschickt. Nach dem Eintreffen am Startpunkt werden sie wieder aktiviert und nehmen ihre normale Verfolgung des Charakters auf. Nach dem Verzehr einer Kraftpille entfernen sich die Geister zunächst von Ms. Pac-Man. Außerdem erscheinen in regelmäßigen Abständen Früchte, die bei Verzehr innerhalb eines bestimmten Zeitraums zusätzliche Punkte bringen.Das Sammeln der Punkte und das Überstehen der für jedes Level vorgegebenen Zeit sind je nach Spielstufe entweder getrennte oder kombinierte Aufgaben für das Erreichen des nächsten Levels. Mit jedem Level erhöht sich zudem die Geschwindigkeit der Geister entsprechend, was den Schwierigkeitsgrad des Spiels steigert. Je nach Level und Schwierigkeitsgrad sind auf dem Spielfeld Tunnel vorhanden, die es Ms. Pac-Man ermöglichen, von einem Rand des Spielfelds nahtlos auf die gegenüberliegende Seite zu wechseln.
 Abb. 1: Ms. Pacman isst einen Geister. |
 Abb. 2: Nach dem Verzehr wird der Geister mit nur Augen dargestellt |
Die Bewegungen von Ms. Pac-Man werden an Kreuzungen durch Benutzerinteraktionen oder vordefinierte Richtungsangaben gesteuert. Zwischen den Kreuzungen bewegt sich die Spielfigur ohne Steuerungseingaben geradlinig weiter oder eine Richtungswechsel eingeleitet werden, sodass Ms. Pac.Man zurückkehrt. Entscheidende Richtungswechsel erfolgen ausschließlich an den Kreuzungspunkten (siehe Abb. 6) und an den Ecken (siehe Abb. 5), was die taktische Komponente des Spiels hervorhebt.
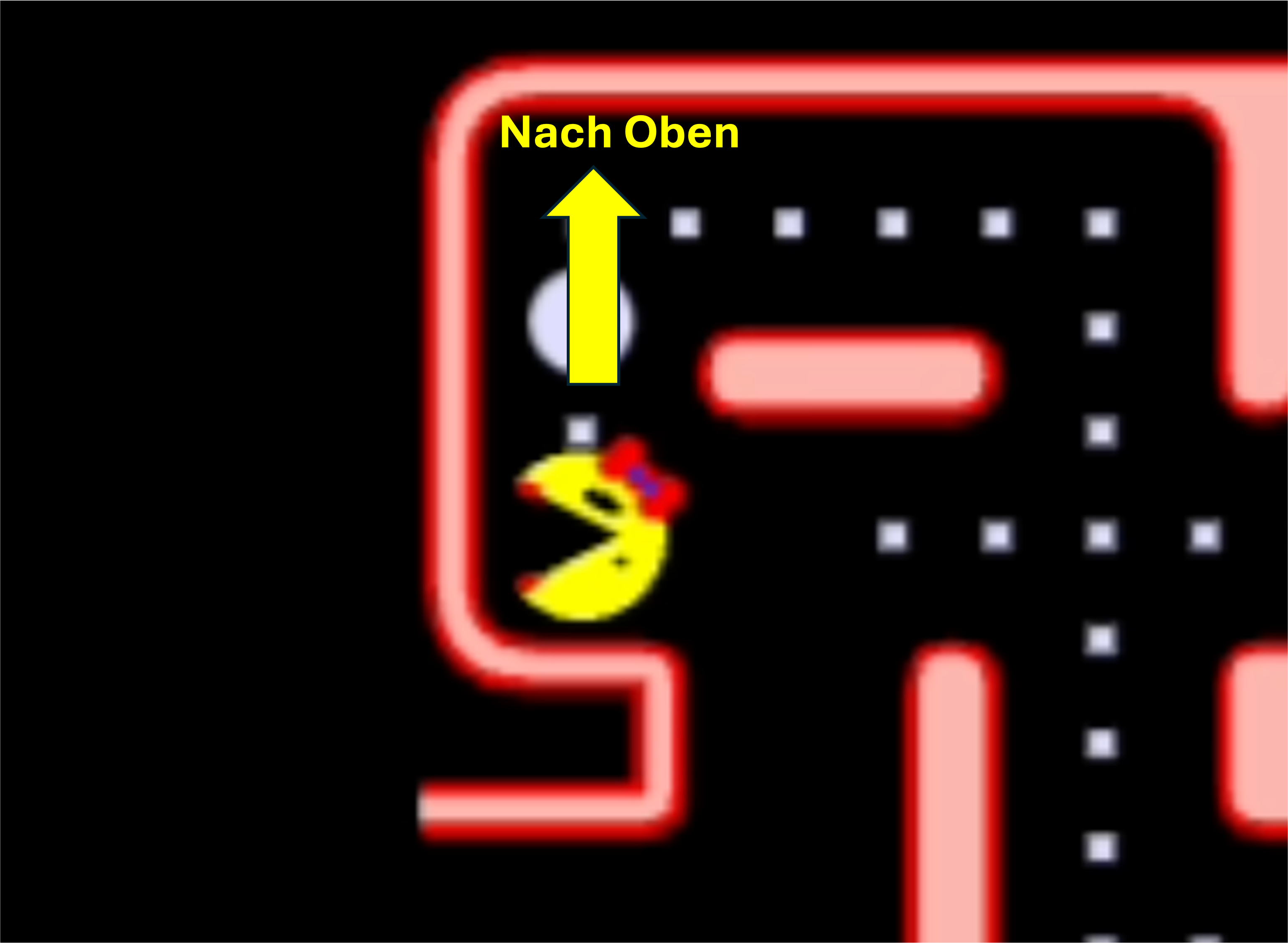 Abb. 5: Ms. Pac-Man ist an der Ecke. Ms. Pac-Man kann entweder nach oben gehen oder zurückkehren. |
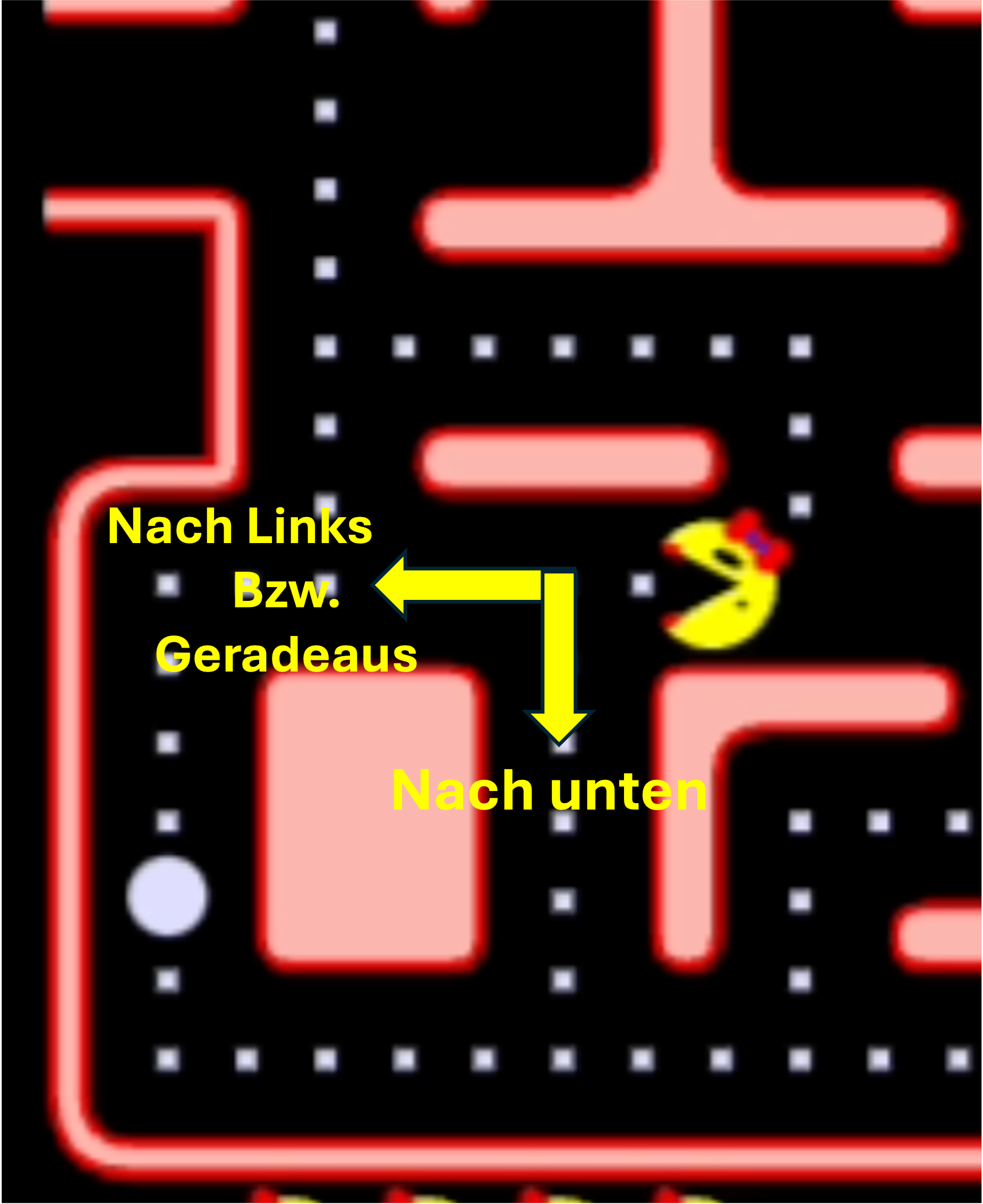 Abb. 6: Ms. Pac-Man kann vorne oder nach unten gehen. |
¶ Warum ist Ms. Pac-Man?
Die Regeln, Strukturen und Eigenschaften von Ms. Pac-Man weisen viele Gemeinsamkeiten mit Pac-Man auf, dennoch stellt sich die Frage, warum Ms. Pac-Man und nicht Pac-Man genauer untersucht werden sollte. Ein wesentlicher Grund hierfür ist, dass die Bewegungsmuster der Geister in Pac-Man festen, regelmäßigen Regeln folgen, während sie in Ms. Pac-Man zufällig generiert werden. Diese Unvorhersehbarkeit erschwert es, das Verhalten der Geister präzise vorherzusagen und macht das Spiel dadurch zu einer idealen Testumgebung. Ein weiterer Grund liegt darin, dass bestimmte Informationen, wie etwa der Schwierigkeitsgrad und die Beschleunigungsrate, in Ms. Pac-Man nicht offengelegt, sondern bewusst geheim gehalten werden[4]. Darüber hinaus bewegen sich die Bonusfrüchte in Ms. Pac-Man zufällig durch das Labyrinth, was eine zusätzliche Ebene der Komplexität einführt Zudem bewegen sich Bonusfrüchte in Ms- Pac-man zufällig durch das Labyrinth[5]. Dieses Zusammenspiel aus Einfachheit und versteckter Komplexität macht Ms. Pac-Man zu einem wertvollen Werkzeug für die Forschung.
¶ Algorithmus
Während in den Spielen verschiedene Algorithmen bzw. Methoden wie generische Programmierung, Suchbaumtechniken oder Reinforcement Learning zum Einsatz kamen, wählten Pepels et al. (2014) für ihre Arbeit den Monte-Carlo-Tree-Search (MCTS)-Algorithmus.
¶ Monte Carlo Tree Search
Monte-Carlo Tree Search (MCTS) ist eine Methode zur Entscheidungsfindung, die zufällige Stichproben im Zustandsraum verwendet und erfolgreich in komplexen Entscheidungs- und Optimierungsproblemen eingesetzt wird. Algorithmus 1[6] bietet eine grundlegende Übersicht über die Schritte einer Variante der Monte-Carlo-Baumsuche. MCTS zeichnet sich durch seine Flexibilität aus, da der Prozess jederzeit unterbrochen werden kann und durch domänenspezifisches Wissen optimiert werden kann. Diese Eigenschaften machen MCTS besonders geeignet für den Einsatz in Spielen, da der Algorithmus in kurzer Zeit optimale Spielzüge basierend auf fundierten Entscheidungen ermitteln kann. Der Algorithmus baut schrittweise einen Baum auf, wobei jeder Knoten Statistiken über gesammelte Belohnungen und Besuche speichert, während die Wurzel die aktuelle Position des Agenten repräsentiert[7]. Der Prozess besteht aus vier iterativen Schritten: Selektion, Erweiterung, Simulation und Rückpropagation. Diese Schritte werden solange ausgeführt, bis eine vorgegebene Rechenbegrenzung – wie eine festgelegte Anzahl von Iterationen, ein Speicherlimit oder eine Zeitbeschränkung – erreicht ist.
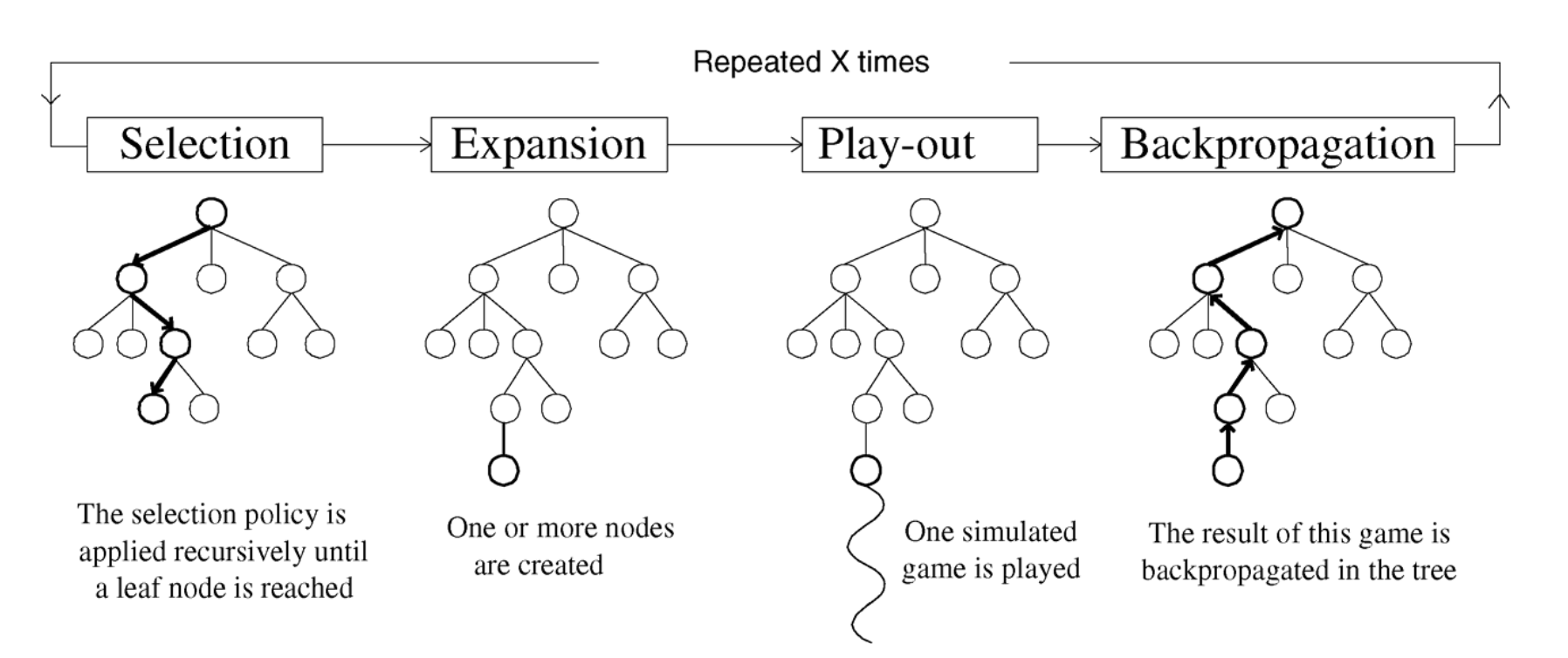
Abb. 7: Strategische Schritte von MCTS.
| 1. | start decision tree {} |
| 2. | while within computational budget do |
| 3. | reset the simulation to |
| 4. | use (usually UCB) to simulate from until a not yet expanded decision |
| 5. | create a new leaf node for that decision and append to |
| 6. | use to roll out the simulation until termination, receiving return |
| 7. | , updates the values , of all parents of |
| 8. | end while |
| 9. | return best child of children |
Die vier Schritte zum dem Algorithmus 1;
- Selection: Tree policy
- Expansion: Add leaf node
- Simulation: Rollout policy
- Back-propagate: Store data ,
Eine detaillierte Beschreibung des Algorithmus 1 ist in den Folien "Sequential Decisions & Monte-Carlo Tree Search" des Moduls "[S23] Einführung in die Künstliche Intelligenz" verfügbar, die auf der Lernplattform ISIS von TU-Berlin bereitgestellt werden.
¶ Die vier essentielle Schritte der MCTS
- Selektion (Selection in eng.)[8]: Die Suche erreicht einen Knoten der nicht Blatt ist sondern Kinder hat, woraufhin ein Kindknoten ausgewählt wird, um die Suche fortzusetzen. MCTS ist eine "First-Best"-Suchmethode, die stets den vielversprechendsten Knoten bevorzugt, es sei denn, der Knoten wurde noch nicht besucht. Der bekannteste Algorithmus, UCT (Upper Confidence Bounds in Trees), behandelt den Baum wie ein Multi-Armed-Bandit-Problem. Er basiert auf den Belohnungswerten und der Anzahl der Besuche jedes Kindknotens. Der UCT-Wert, der den auszuwählenden Knoten bestimmt, wird traditionell mit der UCB1-Formel berechnet.
- Erweiterung (Expansion in eng.)[8:1]: Der Baum wird von der Wurzel aus aufgebaut, die den aktuellen Spielzustand darstellt. Zu Beginn werden Kindknoten hinzugefügt, die die möglichen Zustände repräsentieren, die im nächsten Schritt erreicht werden können. Der Baum wächst weiter, wenn ein Blattknoten ohne Kinder ausgewählt wird. Ein Blattknoten ist ein Zustand, der noch nicht untersucht wurde und nicht das Ende des Spiels darstellt. Er ist noch nicht terminal, weshalb der Baum weiter ausgebaut wird, um die Entscheidungsfindung zu verbessern.
- Simulation (Playout in Paper[7:1]): Ein simuliertes Spiel (Playout) wird durchgeführt, beginnend vom Zustand des neu hinzugefügten Knotens im Baum. Dabei werden Züge entweder zufällig oder gemäß einer heuristischen Strategie gemacht. Das Ziel ist es, einen terminalen Zustand zu erreichen, der das Ende des Spiels darstellt, wie zum Beispiel ein Gewinn, Verlust oder ein Unentschieden. Der Verlauf des Spiels wird dabei vollständig simuliert, ohne weitere Eingriffe oder Optimierungen, um die Belohnung oder den Erfolg der aktuellen Spielstrategie zu evaluieren. Das Ergebnis dieses simulierten Spiels wird anschließend genutzt, um die Statistik des Knotens zu aktualisieren, was die Entscheidung für zukünftige Züge beeinflussen kann.
- Rückpropagation (Back-propagate[8:2] or Backpropagation[7:2] in eng.): Sobald das simulierte Spiel abgeschlossen ist, wird das Resultat sofort vom ausgewählten Knoten zurück zur Wurzel des Baums propagiert. Während dieses Prozesses werden die Statistiken für jeden Knoten, der während des Auswahlschritts besucht wurde, aktualisiert. Zudem wird die Anzahl der Besuche (Visit Count) für diese Knoten erhöht, um zu zeigen, wie oft sie im Verlauf der Suche ausgewählt wurden. Diese Anpassungen ermöglichen eine bessere Einschätzung der Knoten und verbessern so die Entscheidungsfindung im Algorithmus.
¶ Erweiterte Monte-Carlo-Baumsuche in Echtzeit-Spiel
Die Vorteile des MCTS – elegante Lösungen, das Treffen idealer Entscheidungen sowie Erweiterbarkeit und Flexibilität – machen ihn zu einem effektiven Agenten in vielen Spielen, die sogar als Forschungsthema in Wettbewerben dienen. Ein Beispiel dafür ist das Spiel Ms. Pac-Man, wie bereits in diesem Wiki-Artikel erläutert wird. Die Autoren Pepels et al. (2014) setzten MCTS als Agent in Ms. Pac-Man ein, indem sie die Idee von Ikehata und Ito[4:1] (2011) als Ausgangspunkt verwendeten und den Algorithmus in einigen Aspekten weiter verbesserten. Mit dem verbesserten Algorithmus nahmen sie am "2012 World Congress on Computational Intelligence (WCCI’12, Brisbane, Australien)" sowie an der "2012 IEEE Conference on Computational Intelligence and Games (CIG’12, Granada, Spanien)" teil. Dabei erreichten sie jeweils den ersten Platz beim CIG und den zweiten Platz beim WCCI, was ihren Erfolg in beiden Kongressen unterstreicht.
¶ Abbildung des Spiels und Dynamische Tiefgrenze
Um diesen Erfolg zu erzielen, orientierten sich Pepels et al. (2014) an der Arbeit von Ikehata und Ito (2011), die eine feste Tiefgrenze für den Suchbaum in ihrem Algorithmus einführten. Diese Tiefgrenze legte die maximale Anzahl an der Pfadlänge fest, die innerhalb einer einzelnen Simulation berücksichtigt wurden. Allerdings blieb diese Begrenzung in ihrem Ansatz unverändert, unabhängig von den Ergebnissen der Simulationen oder der Rückführung (Backpropagation).
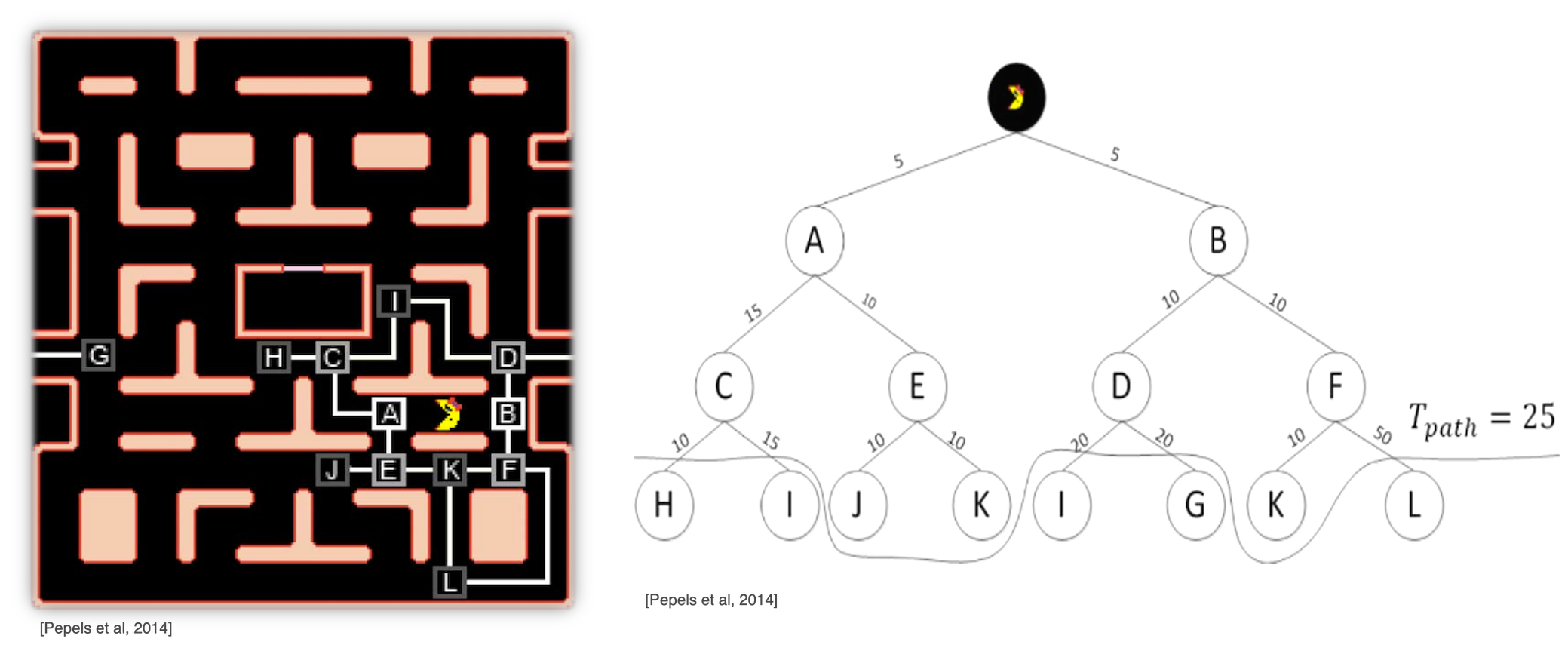
Abb. 9: Baumstruktur des Spiels auf dem Spielfeld und die Baumstruktur mit dem Beispiel von dynamischer Tiefgrenze.
Nun mussten Pepels et al. (2014) das Spiel zunächst für die Anwendung von MCTS anpassen. Für die Strukturierung des Spielfelds führten sie folgende Schritte ein, wie die Umsetzung der Korridore und Kreuzungen in Abbildung 9 veranschaulicht ist;
- Die Korridore, in denen Ms. Pac-Man sich bewegen kann, wurden als Kanten in der Baumstruktur umgesetzt.
- Die Kreuzungen, an denen Entscheidungen getroffen werden müssen, wurden zu Knoten in der Baumstruktur.
Beim Durchlaufen des Baums bewegt sich Ms. Pac-Man entlang einer Kante bis zu einem Knoten. Dort wird entweder ein Blatt erreicht und das Simulationsspiel beginnt oder ein neuer Knoten basierend auf einem Kind des aktuellen Knotens gewählt. Der Baum stellt eine vereinfachte Version des Spielzustands dar, wobei die Bewegungen der Geister nicht durch Knoten repräsentiert sind, sondern durch eine Simulationsstrategie[7:3]. Daher sind die Spielzustände im Baum Annäherungen. Im Gegensatz zu traditionellen Spielen haben sowohl der Spieler als auch der Geister Entscheidungsknoten, und der Spielzustand eines Knotens spiegelt den Zustand für beide Spieler exakt wider[7:4].
Zurückführede Züge im Baum, die zu dem Elternknoten führen, werden nicht über die erste Lage berüksichtigt sowie ihren Tiefe, um einen größeren Unterschied bei den Belohnungen zwischen den verfährten Zügen zu gewährleisten [7:5]. Um dies zu konkretisieren; falls ein Knoten erweitert wird, welcher die Kreuzung repräsentiert, führen die Züge von jedem Knoten , der die Kreuzung datstellt, nicht zur Kreuzung . Der Grund dafür ist die unnötige Erweiterung der Knoten, die durch die durch den Rückkehr entstehenden Notwendigkeit mehrerer Simulationen verursacht wird[7:6].
Für jeden Knoten enthält die Belohnung drei unterschiedliche Attribute, {}, sowohl kumulativ als auch maximiert über die Werte der Kinder des Knotens[7:7]. Beispielsweise Knoten mit der Kindermenge wurde mals besucht und hat die Belohnung anhand der Simulation mit {}. Die kumulative Summe der gespeicherten Belohnungen für beträgt[7:8];
Die Ergebnisse einer Simulation bestehen aus drei Werten[7:9];
1 )2 ) ist die Anzahl der eingenommenen Pillen, normalisiert durch die Anzahl der Pillen zu Beginn des Levels;
3 ) ist die Anzahl der gefressenen Geister, normalisiert durch die gesamte essbare Zeit zu Beginn der Simulation.
Der mittlere Belohnung ist demzufolge[7:10];
Die rekursive Definition maximaler mittleren Belohnung ergibt sich anhand der mittleren Belohnung[7:11];
Der Wert , der für die Auswahl, die Rückausbreitung und die endgültige Zugauswahl eventuell in UCT-Funktion verwendet wird, basiert auf der aktuellen Taktik und wird so entschieden[7:12];
Die Taktik wird entschieden, falls der Schwellenwert der Taktik folgende Situationen aktiv ist[7:13];
- Die Geister-Score-Taktik wird ausgewählt, wenn eine Power-Pille in einem vorherigen Zug gegessen wurde, essbare Geister im Bereich von Ms. Pac-Man liegen und die maximale Überlebensrate über dem Schwellenwert liegt,
- Die Pillen-Score-Taktik ist die Standardtaktik. Es wird angewendet, wenn keine essbaren Geister in Reichweite sind und die maximale Überlebensrate über dem Schwellenwert liegt,
- Die Überlebenstaktik wird verwendet, wenn die maximale Überlebensrate der vorherigen oder aktuellen Suche unter dem Schwellenwert liegt.
Ikehata und Ito (2011) setzten einen Suchbaum ein, dessen Tiefe auf eine feste Anzahl von Kanten begrenzt war, ohne die tatsächliche Distanz der Kanten im Spiel zu berücksichtigen. In Ms. Pac-Man wird die Distanz im Rahmen der Arbeit von Pepels et al. (2014) intern gemessen, wobei beispielsweise der Abstand zwischen zwei benachbarten Pillen als 4 festgelegt ist. Diese dynamische Tiefgrenze des Suchbaums stellt sicher, dass der Agent in gefährlichen Situationen nicht auf schnelle, unsichere Lösungen zurückgreift, da es unter Umständen sicherer ist, einen kürzeren Pfad zu wählen, wenn Ms. Pac-Man in Gefahr ist, anstatt sich auf einen längeren Pfad einzulassen, wie es bei einer festen Baumtiefe der Fall wäre[7:14]. Zudem wird das Punktpotenzial aller möglichen Pfade im Baum aufgrund der einheitlichen Länge der Pfade normalisiert[7:15].
¶ Anpassungen der Wiederverwendung des Suchbaums
Trotz der dynamischen Tiefgrenze des Suchbaums war MCTS im Nachteil, da die Qualität des Algorithmus stark von der Anzahl der Stichproben abhängt. Eine höhere Anzahl von Stichproben führt zwar zu besseren Entscheidungen, ist jedoch in Echtzeit-Spielen unpraktisch, wobei die Entscheigung in 40 ms getroffen werden musste. Die Autoren kamen daher auf eine Idee, bei der eine Präferenzrelation für die Plänen genutzt wurden. Sobald ein Plan für das Folgen eines Pfads in einer Runde ausgewählt wurde, existiert eine Präferenzenrelation mit Plänen , sodass {} . Ms. Pac-Man nutzte dieser Präferenzenrelation, solange sie gültig war[7:16].
Die Präferenzrelation erwies sich jedoch als instabil, da sie durch das Wechseln des Suchbaums nicht mehr aktuelle Werte enthielt[7:17]. Dies brachte für Ms. Pac-Man die Gefahr mit sich, von den Geistern gegessen zu werden. Um dieses Problem zu lösen, entwickelten Pepels et al. im Rahmen ihrer Arbeit zwei Techniken zur Wiederverwendung des Suchbaums.
- Regelbasierte Wiederverwendung[7:18]: Beim Wiederverwenden des Suchbaums und seiner Werte kann sich der Spielzustand auf eine Weise ändern, die von der Suche nicht vorhergesehen wurde. In solchen Fällen sollten die Werte aus früheren Suchen verworfen werden, um Platz für einen neuen Baum zu schaffen, der den aktuellen Spielzustand besser widerspiegelt. Diese Fälle wurden identifiziert und in einer Regelbasis festgelegt. Der bestehende Baum wird verworfen und ein neuer Baum erstellt, sobald eine der definierten Bedingungen erfüllt ist;
- Ms. Pac-Man ist gestorben oder hat ein neues Labyrinth betreten.
- Ms. Pac-Man aß einen blauen Geist oder eine Kraftpille. Dadurch wird sichergestellt, dass sich die Suche sofort darauf konzentrieren kann, (die verbleibenden) Geister zu essen.
- Es gab eine globale Umkehrung. Wenn alle Geister gezwungen werden, sich umzuversen, spiegeln die Werte des zuvor konstruierten Suchbaums nicht mehr den Spielzustand wider.
- Kontinuierliche Werte-Abschwächung[7:19]: Die in den Knoten gespeicherten Werte können über die Zeit abgeschwächt werden, um Ergebnisse aus früheren Zügen kontinuierlich zu nutzen. Dieser Abfall wird erreicht, indem zu Beginn jedes Zugs die kumulierten Punktzahlen und Besuchszahlen jedes Knotens mit einem Rückfallsfaktor multipliziert werden. Die Suche erfolgt dann mit diesen abgeänderten Werten, die den Knoten zugewiesen wurden. Bei der Auswahl eines Zuges wird der Wert eines Knotens durch die Kombination der abgeklungenen Werte und der Belohnungen aus Simulationen des aktuellen Zugs bestimmt. Frühere Studien haben gezeigt, dass das Abklingen heuristischer Werte mittels Abzinsungsfaktoren die Effektivität von Simulationsstrategien verbessern kann. Von den Autoren untersuchte Studien hinwiesen, dass das Abklingen heuristischer Werte mittels Abzinsungsfaktoren die Effektivität von Simulationsstrategien verbessern kann. Die Ergebnisse legen nahe, dass der Rückfallsfaktor dieser Werte ( < < 1) Vorteile gegenüber keiner Rückfallsfaktor () und keiner Wiederverwendung () bietet.
Das Wiederverwenden des Suchbaums bedeutet, dass zu Beginn jedes Zugs entweder eine neue Wurzel basierend auf Ms. Pac-Man letztem Zug gewählt oder ein neuer Baum erstellt wird. War Ms. Pac-Man letzter Standort eine Kreuzung, wird der Kindknoten der ersten Ebene, der dem zuletzt gewählten Zug entspricht, als neue Wurzel festgelegt. Anschließend wird der Baum so umstrukturiert, dass keine Rückwärtsbewegungen über die erste Ebene hinaus möglich sind. Gleichzeitig werden die Pfadlängen im Baum aktualisiert, sodass sie den tatsächlichen Distanzen im Spiel entsprechen. Schließlich werden die Werte in den veränderten Knoten angepasst, sodass sie der Summe ihrer Kindknoten entsprechen.
Zudem setzten Pepels et al. (2014) eine UCT-Auswahlverfahren, falls die Besuchsrate der Kinder über dem Schwellenwert lag. Pepels et al. (2014) klärt es in ihrer Veröffenlichung mit einem Beispiel dafür; "Wenn die Besuchszahlen eines oder mehrerer Kindknoten unter einem bestimmten Schwellenwert liegen, wird eine zufällige, gleichmäßige Auswahl getroffen. Im Fall von Ms. Pac-Man beträgt der Schwellenwert 15, was eine hohe Sicherheit bezüglich der Gefahrlosigkeit des Pfads gewährleistet. Ein ansonsten sicherer und/oder lohnender Knoten könnte aufgrund der stochastischen Natur des Spiels beim ersten Durchlauf zu einem Verlust geführt haben. Durch die Verwendung des Schwellenwerts wird sichergestellt, dass dieser Knoten erneut untersucht wird, wodurch die Sicherheit und der erwartete Nutzen der Entscheidung erhöht werden".
Die Richtlinie, die bestimmt, welches Kind angesichts des aktuellen Knotens ausgewählt werden soll, ist diejenige, die die folgende Gleichung maximiert[7:20]:
Wobei;
- ist die Punktzahl des aktuellen Kindes basierend auf der aktiven Taktik,
- ist die Besucherzahl des Knotens,
- ist die Besuchszahl des aktuellen Kindes und
- is die Explorationskonstante, die durch Experimente bestimmt werden soll.
¶ Simulationsstrategie
In der Simulationsstrategie bewegen sich sowohl die Geister als auch Ms. Pac-Man gleichzeitig. Die Geister blockieren gezielt alle Wege, um Ms. Pac-Man in eine Falle zu locken. Ms. Pac-Man trifft ihre Entscheidungen basierend auf Sicherheitsaspekten, indem sie Geistern ausweicht und sichere Züge wählt. In gefährlichen Situationen, wie etwa wenn ein nicht-essbarer Geist sich ihr nähert oder sie eine Power-Pille gegessen hat, kann sie auch umkehren, um sich zu retten.
¶ Geister-Simulationsstrategie[7:21]:
Die Geister erhalten daher einen zufälligen Zielort-Vektor , der bestimmt, ob ein individueller Geist sich der Vorder- oder der Rückseite von Ms. Pac-Man nähert. Die Geister bewegen sich basierend auf einer -greedy Strategie. Mit einer bestimmten Wahrscheinlichkeit trifft ein Geist in jedem Zug eine zufällige Entscheidung. Mit einer anderen Wahrscheinlichkeit bewegen sich die Geister nach strategischen Regeln, die aus den in vorgeschlagenen Regeln abgeleitet und in diesem Abschnitt detailliert beschrieben sind. Bei der Auswahl eines Geisterzugs während der Simulation gibt es zwei sich gegenseitig ausschließende Fälle zu berücksichtigen: nicht-essbar oder essbar. Darüber hinaus gibt es einen dritten Fall, der in jedem Fall den ausgewählten Zug überstimmt;
Fall 1: Wenn der Geist nicht essbar ist, wird ein Zug gemäß den folgenden Regeln ausgewählt:
- Der Geist wählt einen Zug, der Ms. Pac-Man sofort fängt, wenn dies möglich ist.
- Wenn sich der Geist in unmittelbarer Nähe von Ms. Pac-Man befindet, d. h. innerhalb von sechs Distanz-Einheiten, bewegt sich der Geist entlang des nächsten Weges auf dem kürzesten Pfad zu Ms. Pac-Man.
- Wenn der Geist näher an der Kreuzung ist, die vor Ms. Pac-Man liegt, als Ms. Pac-Man selbst und , wird der Geist direkt zu Ms.Pac-Man vorderer Kreuzung ziehen, wodurch ihr Vorwärtsweg blockiert wird.
- Wenn der Geist auf einer Kreuzung steht, die direkt mit dem Rand verbunden ist, auf dem sich Ms. Pac-Man befindet, und kein anderer Geist auf diesem Rand in dieselbe Richtung zieht, wählt der Geist den Zug, der zu diesem Rand führt, um Ms. Pac-Man basierend auf der -Informationen zu blockieren.
- Andernfalls bewegt sich der Geist näher zu seinem zugewiesenen Zielort. Abhängig von dem Wert von wird das Ziel entweder die nächste Kreuzung vor oder hinter Ms. Pac-Man sein.
Fall 2: Wenn der Geist essbar ist, wird ein Zug ausgewählt, der die Distanz zwischen ihm und Ms. Pac-Man maximiert.
Fall 3: Wenn sich ein Geist auf einem Rand bewegen soll, der derzeit von einem anderen Geist in dieselbe Richtung besetzt ist, wird dieser Zug aus der Auswahl des Geistes entfernt und ein anderer Zug zufällig ausgewählt. Diese Regel stellt sicher, dass sich die Geister im Labyrinth verteilen, wodurch sich die möglichen Fallen- oder Fangpositionen erhöhen. Zudem wird verhindert, dass mehrere Geister Pac-Man gleichzeitig (oder in ähnlichen Entfernungen) verfolgen.
¶ Ms. Pac-Man Simulationsstrategie[7:22]
Die Bewegungen von Ms. Pac-Man werden nach Sicherheitsaspekten und potenziellen Belohnungen priorisiert. Wenn mehrere Züge die gleiche höchste Priorität haben, wird zufällig ein Zug ausgewählt. Bevor die Strategie im Detail erläutert wird, muss zunächst das Konzept eines sicheren Zugs definiert werden. Ein sicherer Zug ist jeder Schritt, der zu einem Vorteil führt, der;
- auf dem kein nicht-essbarer Geist in Ms. Pac-Man Richtung unterwegs ist,
- dessen nächste Kreuzung sicher ist, d. h. Ms. Pac-Man wird die nächste Kreuzung immer vor einem nicht-essbaren Geist erreichen.
Während der Simulation bewegt sich Ms. Pac-Man an einer Kreuzung gemäß einem priorisierten Regelset:
- Wenn essbare Geister erreichbar sind, das heißt, die Zeit, um einen Geist zu erreichen, kürzer ist als die verbleibende Essenszeit, wird ein sicherer Zug zum nächstgelegenen essbaren Geist entlang des kürzesten Pfads ausgewählt.
- Führen sichere Züge zu einem Rand, der noch nicht geräumt ist, d. h. Pillen enthält, wird dieser Zug ausgeführt.
- Falls alle sicheren Ränder geräumt sind, wird ein zufälliger Zug zu einem sicheren Rand gewählt.
- Ist kein sicherer Zug verfügbar, wird ein zufälliger Zug ausgewählt.
Ms. Pac-Man kann auf der aktuellen Kante allerdings in folgende Situationen umkehren;
- Falls ein nicht-essbarer Geist sich auf dem aktuellen Pfad in Richtung Pac-Man bewegt;
- Eine Power-Pille wurde aufgenommen; in diesem Fall wird der Zug gewählt, der zum nächsten essbaren Geist führt.
Für den Fall, dass die oben genannte Situationen vorkommt, während Ms. Pac-Man bereits auf der aktuellen Kante umgekehrt ist, kann sie nochmal umkehren, sonst läuft sie bis zum nächsten Knoten.
¶ Langfristige Ziele
Wie bei Pac-Man gibt es auch bei Ms. Pac-Man Zeitaufgaben, in denen sie innerhalb einer vorgegebenen Zeitspanne bestimmte Ziele erreichen muss. Um diese Aufgaben erfolgreich zu bewältigen, muss Ms. Pac-Man im Spiel bleiben, obwohl die Gefahr durch zunehmende Komplexität und stärkere Gegner steigt. Laut Pepels et al. (2014) erhält Ms. Pac-Man bei einer Punktzahl von 10.000 ein zusätzliches Leben, was es ermöglicht, eine noch höhere Punktzahl zu erzielen. Um Ms. Pac-Man ähnlich wie Menschen zu motivieren, kodierten Pepels et al. (2014) einen dynamischen -Wert, der den Anreiz zur Interaktion mit Geistern darstellt. Dieser Wert wurde von den Autoren dynamisch angepasst, um langfristige Ziele mit höheren Punktzahlen zu fördern. Eine der Strategien zur Förderung von Ms. Pac-Man ist die Anpassung der Power-Pillen-Belohnung basierend auf der Entfernung der Geister. Wenn eine Pille gegessen wird und die Geister nicht essbar sind, erreicht einen Wert von mehr als 0,5 am Ende der Aktion[7:23]. Ist die Entfernung zu den Geistern so groß, dass sie nicht überwunden werden kann, wird auf 0 gesetzt. Wenn hingegen 0,5 beträgt und eine Power-Pille gegessen wird, wird die Belohnung der Pille durch erhöht. Dieses System stellt sicher, dass Ms. Pac-Man die Power-Pille innerhalb der erforderlichen Zeit isst, was ihr zusätzliche Punkte ermöglicht und sie vor den Geistern schützt.
Da in einigen Fällen die die Punktzahl erfüllt werden musste, weil je schneller die Punkte gesammt wurde, desto schneller Ms. Pac-Man das Spiel beenden. Um dies zu gewährleisten, wird basierend auf der Anzahl der Pillen an den Kanten und ihrer Entfernung von Ms. Pac-Man angepasst. Pillen, die weit von Ms. Pac-Man entfernt sind, erhalten eine höhere Belohnung, da die große Entfernung ein erhöhtes Risiko für Ms. Pac-Man darstellt. Daher werden weit entfernte Pillen priorisiert und Ms. Pac-Man hingesteuert. Die Kanten-Belohnung in der Arbeit von Pepels et al. (2014) wurde wie folgt definiert: , wobei und die gelöschte Kante repräsentiert. Da die maximale Belohnung für die Kanten begrenzt wurde, wird berechnet und anschließend normalisiert. Dies gewährleistet eine angemessene Verteilung der Belohnungen.
Für die finale Backpropagation von Pepels et al. (2014) wird zunächst die aktuelle Taktik bewertet. Wenn die Überlebensrate unter dem festgelegten Schwellenwert liegt (), wechselt der Algorithmus zur Überlebenstaktik und propagiert Werte basierend auf der Maximierung von . Liegt die Überlebensrate jedoch über dem Schwellenwert, werden die Punktzahlen gemäß der aktuellen Taktik ermittelt. In diesem Fall werden die Knoten der ersten Ply-Ebene bewertet, und der Knoten mit der höchsten Punktzahl, der gleichzeitig die Bedingung erfüllt, wird für die Auswahl herangezogen. Sollte keine der Taktiken eine lohnenswerte Belohnung bieten (d. h. für alle Knoten), wird die Taktik gemäß einer festgelegten Reihenfolge ersetzt: Zuerst wird die Ghost-Taktik, dann die Pille-Taktik und zuletzt die Überlebenstaktik verwendet. Diese Umstellung erfolgt, wenn zum Beispiel die nächste Pille oder der essbare Geist außerhalb des Suchbaums liegt.
¶ Fazit
Pepels et al. entwickelten den MCTS-Algorithmus und implementierten ihn erfolgreich. Durch die vorgenommenen Verbesserungen konnte der Spiel-Agent von Pepels et al. (2014) bei den Konferenzen jeweils den ersten und zweiten Platz erzielen.
Während eine hervorragende Spielstrategie für Ms. Pac-Man die Sicherheit des Agents gewährleistete, ermöglichte die Strategie der langfristigen Zielverfolgung – trotz der Gefahr durch die Geister – das Erreichen hoher Punktzahlen. Die Wiederverwendung des Suchbaums durch die Erzeugung neuer Baumstrukturen und der Einsatz des RückfallFaktors ermöglichten es, jedes Pixel des Spiels effizient zu erkunden. Unsichere und überstürzte Entscheidungen wurden durch die Einführung einer Tiefengrenze vermieden, was jedoch bedaurlicherweise kurz behandelt wurde. Alle Prozesse mussten innerhalb eines Zeitrahmens von 40 ms ablaufen, was eine zusätzliche Zielsetzung darstellte.
Trotz dieser Fortschritte berichten Pepels et al. (2014), dass die implementierten Ideen und Verbesserungen nicht ausreichten. Der Agent war in schwierigeren Spielumgebungen nicht in der Lage, selbst die erste Runde zu überstehen. Diese Beobachtung deutet darauf hin, dass der Algorithmus weiteres Verbesserungspotenzial bietet und für zukünftige Optimierungen offen ist.
Pseudocode und Beschreibung des Algorithmus[7:24]
Diese Informationen zu veranschaulichen teilten Pepels et al. (2014) für eine Simulation folgende Algorithmus 2;
| 1. | node , cumulative path length ): |
| 2. | if then |
| 3. | return Playout(p) |
| 4. | else if then |
| 5. | for do |
| 6. | |
| 7. | Add new leaf to the tree |
| 8. | |
| 9. | |
| 10 | return : |
| 11 | else |
| 12. | Let be the tactic set at the root |
| 13. | . . |
| 14. | for do |
| 15. | Let be the action associated with child |
| 16. | . . |
| 17. | |
| 18. | Select move that maximizes |
| 19. | |
| 20. | if then |
| 21. | |
| 22. | |
| 23. | return |
| 24. | |
| 25. | |
| 26. | return |
Pepels et al. (2014) beschreiben den Ablauf folgende Texte: Von der Wurzel ausgehend übergibt jeder rekursive Aufruf den neuen Zustand eines Kindknotens weiter, bis ein erweiterbarer Knoten erreicht wird. Sobald dies geschieht, fügt das Verfahren die Kinder dieses Knotens dem Baum hinzu und startet eine Simulation von einem dieser neuen Kinder aus. Jeder Knoten speichert verschiedene Bewertungen, darunter eine, die abhängig von der aktuellen Taktik verwendet wird, um die Suche zu steuern. Zusätzlich werden für jede durchschnittliche Bewertung zwei Versionen geführt: eine alte und eine neue. Die alten Bewertungen repräsentieren die Summe der abgeklungenen Werte aus früheren Suchvorgängen, während die neuen Bewertungen ) speziell für die aktuelle Suche aktualisiert werden. Diese Werte werden zwischen den Suchvorgängen mithilfe der Gleichungen aktualisiert, die weiter unten aufgeführt sind. Die Tiefe des Baums variiert in Abhängigkeit von der im Spiel gemessenen Distanz zwischen den Knoten. Um sicherzustellen, dass das festgelegte Distanzlimit nicht überschritten wird, wird während der Suche eine kumulative Distanz von der Wurzel aus geführt (siehe Zeile 2). Ein Knoten gilt als erweiterbar, wenn seine Entfernung von der Wurzel unterhalb des Distanzlimits liegt und sich keines seiner Kinder bereits im Baum befindet. Wenn ein Knoten erweiterbar ist, werden alle seine Kinder dem Baum hinzugefügt, wie zwischen den Zeilen 4 und 9 beschrieben. Anschließend simuliert das -Verfahren den verbleibenden Spielverlauf. Dabei liefert es ein Ergebnis-Tupel das mit dem ersten Kindzustand verknüpft ist, der von aus erreicht wurde. Das -Verfahren am Knoten aktualisiert den entsprechenden kumulierten Wert für die aktuelle Taktik erhöht den Überlebensscore und zählt die Besuche am Knoten hoch. Gleichzeitig wird der Maximalwert basierend auf Gleichung angepasst. Es ist zu beachten, dass der Abklingprozess zwischen den Suchvorgängen den Wert von nicht beeinflusst, da die Abklinggleichungen und die Durchschnittswerte unverändert lassen. Der nächste Zustand ergibt sich durch eine Simulation, die in Zeile 19 vom Knoten aus gestartet wird. Der Übergang von simuliert die Bewegung vom aktuellen Knoten zum Kind . Sollte Ms. Pac-Man während dieses Übergangs im MCTS-Baum sterben, wird die Simulation abgebrochen, und das -Verfahren wird vom Elternknoten aus gestartet. Wie in den Zeilen 20 bis 22 dargestellt, beginnt die Simulation dann erneut ab . Überlebt sie jedoch, wird die Pfadlänge entlang als berechnet, und die Suche wird ab in Zeile 24 fortgesetzt. Zwischen den Suchvorgängen gibt es zwei wesentliche Änderungen am Baum. Erstens wird der Baum nach Wiederverwendung des Suchbaums neu strukturiert. Danach werden an jedem Knoten des neuen Baums und für jede Taktik weitere Aktualisierungen vorgenommen.
Hinweis: Die ganze Beschreibung des Algorithmus wurde von Pepels et al. (2014) übernommen.
¶ Ausgangspunkt und Inspiration
PEPELS, Tom; WINANDS, Mark HM; LANCTOT, Marc. Real-time monte carlo tree search in ms pac-man. IEEE Transactions on Computational Intelligence and AI in games, 2014, 6. Jg., Nr. 3, S. 245-257.[IEEE Xplore]
Hinweis: Für die Verbesserung der Verständlichkeit und wissenschaftlicher Schreibart wurde ChatGPT-4o angewendet.
¶ Referenzen
¶ Abbildungen
- Abb.1 bis Abb.6 - sind die Schnitte, die aus dem von dem Autor (Nazim Yolcu) des Wiki-Artikel selbst gepieltem Spiel aufgenommen wurden.
- Abb. 7 und Abb. 9 - PEPELS, Tom; WINANDS, Mark HM; LANCTOT, Marc. Real-time monte carlo tree search in ms pac-man. IEEE Transactions on Computational Intelligence and AI in games, 2014, 6. Jg., Nr. 3, S. 245-257. IEEE Xplore
- Abb. 8 - SAMOTHRAKIS, Spyridon; ROBLES, David; LUCAS, Simon. Fast approximate max-n monte carlo tree search for ms pac-man. IEEE Transactions on Computational Intelligence and AI in Games, 2011, 3. Jg., Nr. 2, S. 142-154.IEEE Xplore
¶ Litaratur und wissenschaftliche Veröffentlichungen
BOM, Luuk; HENKEN, Ruud; WIERING, Marco. Reinforcement learning to train Ms. Pac-Man using higher-order action-relative inputs. In: 2013 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL). IEEE, 2013. S. 156-163. IEEE Xplore ↩︎
BERNAL-MERINO Miguel Á. A brief history of game localisation. TRANS: revista de traductología, 2011, Nr. 15, S. 11-17. Dialnet ↩︎
IKEHATA, Nozomu; ITO, Takeshi. Monte-carlo tree search in ms. pac-man. In: 2011 IEEE Conference on Computational Intelligence and Games (CIG'11). IEEE, 2011. S. 39-46. IEEE Xplore ↩︎ ↩︎
ROHLFSHAGEN, Philipp, et al. Pac-man conquers academia: Two decades of research using a classic arcade game. IEEE Transactions on Games, 2017, 10. Jg., Nr. 3, S. 233-256. IEEE Xplore ↩︎
TOUSSAINT, Marc Sequential Decisions & Monte-Carlo Tree Search. Artificial Intelligence Summer 2023. Technical University of Berlin. TU-Berlin ISIS ↩︎
PEPELS, Tom; WINANDS, Mark HM; LANCTOT, Marc. Real-time monte carlo tree search in ms pac-man. IEEE Transactions on Computational Intelligence and AI in games, 2014, 6. Jg., Nr. 3, S. 245-257. IEEE Xplore ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
ALHEJALI, Atif M.; LUCAS, Simon M. Using genetic programming to evolve heuristics for a Monte Carlo Tree Search Ms Pac-Man agent. In: 2013 IEEE Conference on Computational Inteligence in Games (CIG). IEEE, 2013. S. 1-8. IEEE Xplore ↩︎ ↩︎ ↩︎