Monte Carlo Tree Search ist ein Algorithmus zur Entscheidungsfindung, welcher auf einer Baumstruktur basiert. Dabei wird oft ein sehr großer Suchraum durchsucht um ein Problem zu lösen.
Im Suchbaum repräsentiert ein Knoten einen Zustand bzw. eine Konfiguration des Problems und die Kanten eine mögliche Aktion aus diesem Zustand in einen neuen Zustand.
Die Basis von MCTS arbeitet ohne Heuristiken, das bedeutet es wird keine zusätzliche Information über das Problem benötigt außer den Übergängen von einem Zustand zu einem anderen, meist Regeln. Allerdings kann durch wissensbasierte Suche MCTS verbessert werden.
MCTS ist ein sogenannter anytime Algorithmus. Das bedeutet er kann zu jedem Zeitpunkt gestoppt werden, um die Ergebnisse zu analysieren und zu benutzen.
¶ Phasen von MCTS
Monte Carlo Tree Search basiert auf vier Phasen: Selection, Expansion, Simulation und Backpropagation, welche im weiteren Verlauf erläutert werden. Diese werden wiederholt ausgeführt bis eine Grenze erreicht wird. Diese Grenze kann zum Beispiel ein zeitlicher Grenzwert oder eine maximale Anzahl an Iterationen sein.
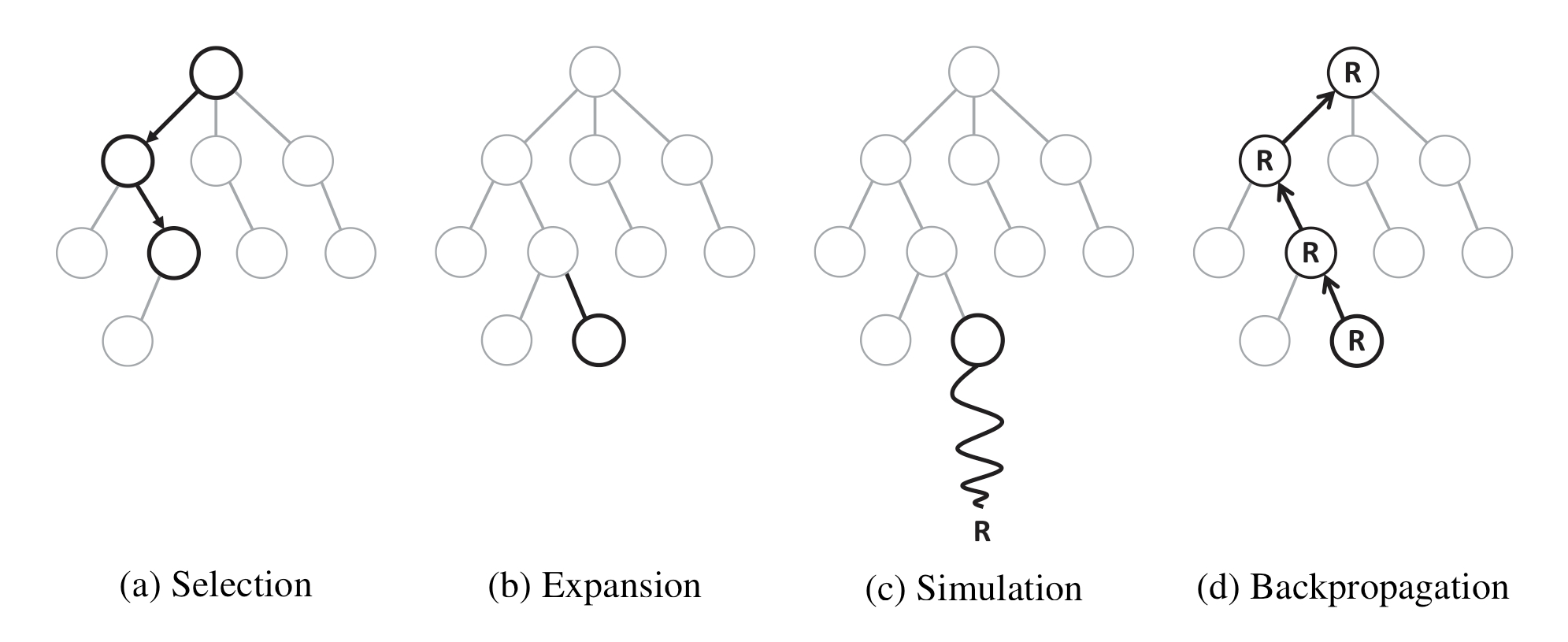
¶ Phase 1 - Selection
In dieser Phase wird der bisher aufgebaute Suchbaum durchsucht. Dabei beginnt der Algorithmus immer am Wurzelknoten und sucht gemäß einer Selection Policy auf jeder Ebene einen Knoten aus. Die Phase ist beendet, sobald ein Blattknoten ausgewählt wird. Ein Blattknoten ist ein Knoten, der noch nicht vollständig expandiert wurde oder von dem eine Expandierung nicht mehr möglich ist. Blattknoten sind also sowohl Endzustände als auch Zustände, welche Kindknoten haben von welchen noch nie simuliert wurde.[1]
¶ Phase 2 - Expansion
Falls die Selection Phase nicht mit einem Endzustand geendet ist, wird nun expandiert. Das bedeutet es wird nun ein neuer Knoten in die Baumstruktur aufgenommen der im Verlauf des Pfades noch nicht entdeckt wurde. Der neue Knoten kann durch eine Aktion aus dem letzten Knoten der Selection Phase erreicht werden. Sollte es sich dabei um einen Endzustand handeln wird direkt zur Backpropagation übergegangen. Andernfalls wird die Simulationsphase eingeleitet.[1:1]
¶ Phase 3 - Simulation
Die Simulation Phase spielt nun auf dem durch die Expansion Phase zurückgegebenen Spielzustand so lange zufällige Spielzüge, bis das Spiel in einem Endzustand angekommen - also entweder gewonnen oder verloren - ist und gibt dementsprechend 1/0 bei einem Win/Loss als "Payout" zurück. Dabei kann die Strategie, die zur Auswahl der Spielzüge verwendet wird, sowie der Payout, je nach Spiel angepasst werden, um das Ergebnis zu verbessern. In Spielen mit der Möglichkeit eines Unentschiedens muss zudem noch festgelegt werden, was dessen Payout ist.[1:2] [2]
¶ Phase 4 - Backpropagation
Die Backpropagation läuft nun rückwärts vom simulierten Blattknoten zur Wurzel zurück. Dabei wird jeder Knoten auf dem Weg aktualisiert; Die Anzahl an Simulationen wird um eins erhöht, die Anzahl gewonnener Spiele wird um den durch die Simulation Phase zurückgegebenen Payout erhöht. Diese Werte werden von der Selection Policy in darauffolgenden Iterationen verwendet.[1:3]
¶ Selection Policy
Das Ziel des Auswahlverfahrens ist es, einen Ausgleich zwischen Exploration und Exploitation zu schaffen. Unter Exploration ist das Erkunden neuer Züge zu verstehen, wohingegen Exploitation das gezielte Ausnutzen bereits als gut bewerteter Züge beschreibt.
Es gibt unterschiedliche Möglichkeiten einen Knoten auszuwählen aber die wohl am weitesten verbreitete Methode ist Upper Confidence Bounds applied for Trees (UCT).
¶ UCT
Hierbei wird der Kindknoten mit maximalem Wert nach folgender Formel[3] ausgewählt:
Dabei ist der aktuelle Knoten. Die Formel berechnet für jeden Kindknoten , die Gewinnrate , also die Anzahl der Gewinne mit durch die Gesamtanzahl der Spiele mit . Dieser Term steht Exploitation, also dass gute Züge wiederholt werden. Hinzu wird der explorative Faktor addiert. ist die Anzahl der Besuche des aktuellen Knoten und die Anzahl der Besuche des Kindknoten . Dieser Wert wird mit der Konstante multipiziert, welche die Exploration reguliert. Wenn ein Knoten selten besucht wird, ist klein, was in einem größeren explorativen Term resultiert, also wird der Knoten eher ausgewählt.
Sollte ein Knoten noch nie besucht worden sein, so wird zurückgegeben und somit neu expandiert.
¶ Pseudocode MCTS
def monte_carlo_tree_search(root):
while limit_not_exceeded:
leaf = select(root)
new_node = expand(leaf)
simulation_result = rollout(new_node)
backpropagate(leaf, simulation_result)
return best_child(root)
def select(node):
while fully_expanded(node):
node = selection_policy(node.children)
return node
def expand(node):
if not terminal(node):
return unvisited(node.children)
return node
def rollout(node):
while not terminal(node):
node = play_random_move(node)
if game_won(node):
return 1
else:
return 0
def backpropagate(node, result):
while node is not null:
node.times_played += 1
node.times_won += result
node = node.parent
Es wird monte_carlo_tree_search() aufgerufen, welche wiederum alle anderen Funktionen aufruft, um die bestmögliche Lösung auszuwählen. Dabei wird der Wurzelknoten root als Parameter übergeben.
select() wählt so lange einen Konten aus, bis die Methode einen Knoten erreicht, dessen Kinder noch nicht vollständig in den Suchbaum aufgenommen wurden, das wird mit fully_expanded() überprüft. Dabei wird eine indiviuelle selection_policy() verwendet.
expand() wählt nun einen Kindknoten mithilfe von unvisited() aus, der noch nicht im Entscheidungsbaum ist, also noch nie besucht wurde. Sollte der Knoten ein Endknoten sein wird dieser selbst zurückgegeben. Das wird mit terminal() überprüft.
rollout() simuliert mithilfe einer zufälligen Zugauswahl play_random_move() das Spiel so lange, bis ein Gewinner feststeht und gibt anschließend den entsprechenden Payoff zurück.
backpropagate() aktualisiert jeden Knoten des Spielbaums auf dem Weg zurück zur Wurzel. Die Anzahl an Simulationen node.times_played wird um 1 erhöht, die Anzahl der gewonnenen Spiele/der Payout node.times_won wird um den von rollout() berechneten Payout erhöht.
¶ Anwendungsbeispiele
Monte Carlo Tree Search wurde anfangs entwickelt für Computer Players in Go hat aber mittlerweile weitrechende Anwendungen gefunden. So wird MCTS in vielen Spielen wie 2048, Hex, Havannah, Durak, Chain Reaktion und weitere benutzt.
Anmerkung: Amélie Schall ist für die ersten zwei Phasen des Algorithmus, inklusive Selection Policy, sowie eine kurze Einführung zuständig und Moritz Bühner ist für die letzten zwei Phasen zuständig.
¶ Referenzen
Die Links der Referenzen 1-3 sowie Abb 1 wurden das letzte mal geprüft am 08.07.2025 um 12:00.
Abb 1: James, S., Konidaris, G., & Rosman, B. (2017, February). An analysis of monte carlo tree search. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 31, No. 1). download
Świechowski, M., Godlewski, K., Sawicki, B., & Mańdziuk, J. (2023). Monte Carlo tree search: A review of recent modifications and applications. Artificial Intelligence Review, 56(3), 2497-2562. pdf ↩︎ ↩︎ ↩︎ ↩︎
angelehnt an Browne, C. B., Powley, E., Whitehouse, D., Lucas, S. M., Cowling, P. I., Rohlfshagen, P., ... & Colton, S. (2012). A survey of Monte Carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1), 1-43.pdf ↩︎ ↩︎
Stankiewicz, J.A., Winands, M.H.M., Uiterwijk, J.W.H.M. (2012). Monte-Carlo Tree Search Enhancements for Havannah. In: van den Herik, H.J., Plaat, A. (eds) Advances in Computer Games. ACG 2011. Lecture Notes in Computer Science, vol 7168. Springer, Berlin, Heidelberg. pdf ↩︎