Proof-Number Search (kurz PN-Search oder PNS) ist ein Algorithmus, der den spieltheoretischen Wert in Spielbäumen von zwei-Spieler-Spielen bestimmt.
Er wurde 1994 von L. Victor Allis, Maarten van der Meulen und H. Jaap van den Herik auf der Grundlage von conspiracy-number search (vorgestellt in den 80er-Jahren von McAllester[1][2]) entwickelt und in diesem [3] Paper vorgestellt, das diesem Wiki-Artikel als Grundlage dient.
¶ Ansatz[3:1]
Um den spieltheoretischen Wert, den Ausgang des Spiels bei optimalem Spiel beider Parteien, zu ermitteln, wird zuerst eine Annahme über den Ausgang des Spiels getroffen. Daraufhin ist es das Ziel des Algorithmus, diese Annahme mit Hilfe der namensgebenden Proof- und Disproof-Zahlen schnellstmöglich zu beweisen oder zu widerlegen.
Das ist einfacher für Spiele mit binärem Ausgang, hier wird ein Sieg für die in der aktuellen Position ziehenden Partei angenommen.
Für Spiele mit mehrwertigem Ausgang, wie beispielsweise Awari oder Go mit Punktwertung, ist dies etwas komplizierter. Hier wird die Annahme getroffen, dass die ziehende Partei das Spiel mit mindestens k Punkten gewinnt, für ein gewähltes k (für genauere Betrachtung siehe unten).
¶ UND-/ODER-Bäume
Spielbäume bestehen aus sog. UND- und ODER-Knoten, und werden deshalb auch als UND-/ODER-Bäume (engl: AND-/OR-Trees) bezeichnet.
Die Namen entsprechen dabei Min- und Max-Knoten aus Minimax, und hängen von der Partei ab, von der aus man den Spielbaum betrachtet. Will man den Spielwert aus Sicht von Weiß bestimmen, so sind alle Knoten, in denen Weiß zieht, ODER-Knoten, da nur für einen der Kindknoten eine Gewinnstrategie existieren muss.
Die Knoten, in denen Schwarz zieht, heißen UND-Knoten, da Schwarz hier in allen Kindknoten verlieren muss, damit Weiß gewinnt.
¶ Theoretische Grundlagen[3:2]
Im folgenden werden einige für das Verständnis essentielle Grundlagen für den Algorithmus vorgestellt.
¶ Vielversprechendster Knoten
Minimax verfolgt einen depth-first-Ansatz, durchläuft also die Knoten des Spielbaums in einer festgelegten Reihenfolge, um letztendlich den spieltheoretischen Wert zu ermitteln.
PN-Search dagegen setzt bei der Wahl des nächsten Knotens einen best-first-Ansatz. Hierbei wird gezielt derjenige Knoten ausgewählt, der im optimalen Fall am schnellsten dazu beiträgt, die anfangs getroffene Annahme zu beweisen oder zu widerlegen. Dieser Knoten wird als vielversprechendster Knoten (engl: most-proving node) bezeichnet.
¶ Beispiel
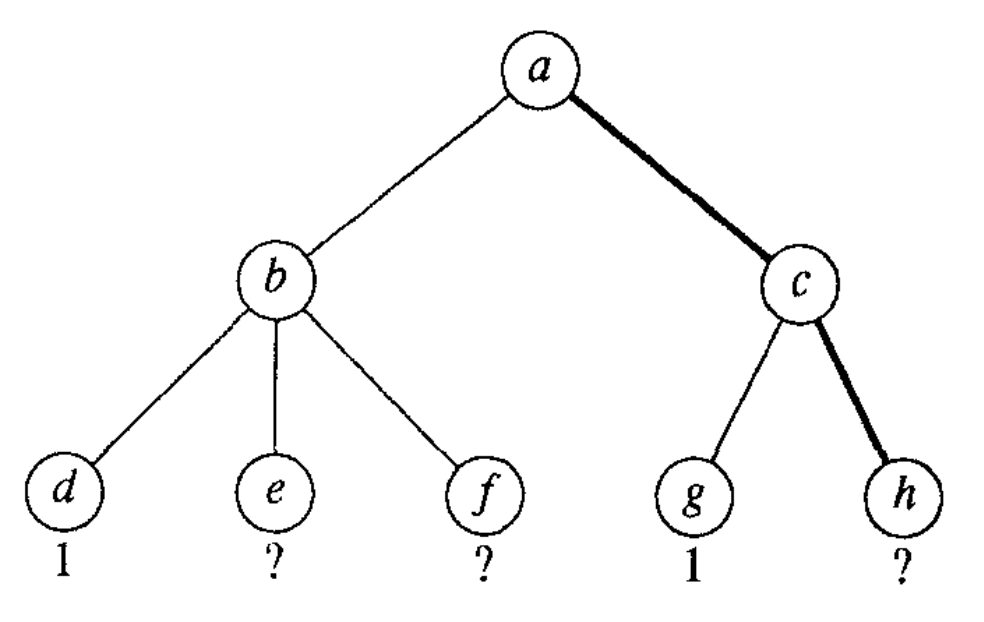
Abb. 1 Beispielhafter Spielbaum mit vielversprechendstem Knoten h
In Position a ist Weiß am Zug, und hat zwei Zugmöglichkeiten die zu Position b und c führen, in denen Schwarz zieht.
h ist der vielversprechendste Knoten, denn sollte sich h als Gewinnposition für Weiß erweisen, hätte Weiß von Position a aus eine sicher zum Sieg führende Zugmöglichkeit und somit das Spiel gewonnen.
Der andere Teilbaum ist weniger vielversprechend, denn Weiß müsste sowohl in e als auch in f gewinnen. Da Schwarz in b am Zug ist, wäre nur in diesem Fall ein Sieg für Weiß garantiert.
Ist der aktuelle Knoten ein UND-Knoten, ist es einfacher, die Annahme zu widerlegen, als sie zu beweisen. Denn das kann durch einen einzelnen Kindknoten geschehen (der Beweis müsste mit allen Kindknoten geführt werden).
¶ Proof-/Disproof-Zahlen
Um den aktuell vielversprechendsten Knoten zu finden, werden für jeden Knoten im Spielbaum Proof- und Disproof-Zahlen gespeichert, die den minimalen nötigen Aufwand beschreiben, um die Annahme zu beweisen/widerlegen. Einen neuen Knoten zu betrachten, wird dabei mir einer imaginären Aufwandseinheit berechnet.
Die beiden Zahlen können dabei als Paar angegeben werden, wobei die Proof- und die Disproof-Zahl ist.
Die konkreten Proof- und Disproof-Zahlen hängen dabei von der Art des Knotens ab:
- Bekannte, aber unbesuchte Knoten, erhalten den Wert (vgl. Abb. 2 Knoten
i).
Um an solch einem Knoten die Annahme zu zeigen oder zu widerlegen, reicht es, im glücklichen Fall, nur diesen Knoten aufzudecken. - Ein Knoten mit bekanntem Spielwert (Bspw. Sieg für Weiß) erhält, je nachdem ob der Wert die Annahme unterstützt oder nicht, das Wertepaar oder (vgl. Abb 2. Knoten
h).
Wenn die Annahme durch den Spielwert bereits bewiesen wurde, beträgt der Aufwand dazu , denn kein weiterer Knoten muss expandiert werden. Gleichzeitig ist es in diesem Fall unmöglich, die Annahme zu widerlegen. Für den entsprechenden Aufwand wird deswegen gewählt. - ODER-Knoten (vgl. Abb. 2 Knoten
a):- Die Proof-Zahl ist das Minimum der Proof-Zahlen der Kindknoten.
- Die Disproof-Zahl ist die Summe der Disproof-Zahlen der Kinder.
- UND-Knoten (vgl. Abb. 2 Knoten
bundc):- Die Proof-Zahl ist die Summe der Proof-Zahlen der Kinder.
- Die Disproof-Zahl ist das Minimum der Disproof-Zahlen
¶ Beispiel
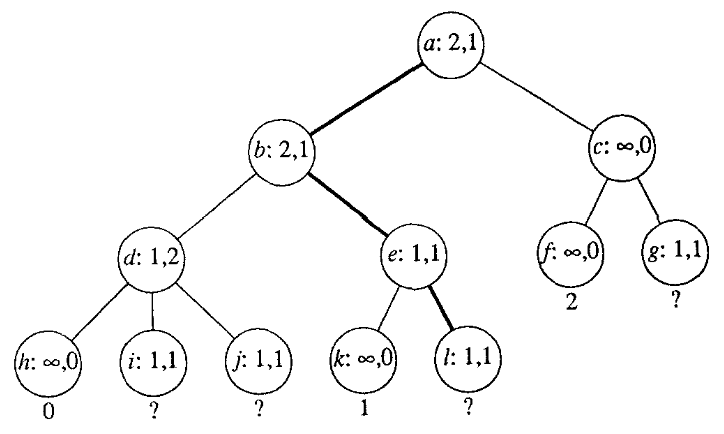
Abb. 2 beispielhafter Spielbaum mit eingezeichneten Proof- und Disproof-Zahlen
Nachdem ein Knoten expandiert wurde, werden die Proof-/Disproof-Zahlen im Baum aktualisiert. Der vielversprechendste Knoten wird dann mithilfe dieser Zahlen bestimmt.
¶ Mehrwertige Spiele
Mehrwertige Spiele müssen gesondert betrachtet werden, da der Algorithmus in seiner Grundform nur für binäre Ergebnisse konzipiert ist. Hier kann nicht nur nach einem Sieg gesucht werden.
Um den Algorithmus anzuwenden, wird ein k aus dem Wertebereich der möglichen Spielausgänge gewählt. Anschließend wird das Spiel durch die folgenden Regeln so behandelt, als hätte es einen binären Ausgang:
- Alle Werte werden als positiver Ausgang und
- alle Werte als negativer Ausgang gewertet.
Dadurch kann der Algorithmus wie bisher beschrieben angewendet werden.
Noch nicht beachtet wurde bis jetzt die Wahl von k.
Um den spieltheoretischen Wert ermitteln, können mit einer linearen oder binären Suche verschiedene Werte getestet und bewiesen/widerlegt werden. Dadurch kann der Spielausgang durch eine Folge von zwei-wertigen Analysen ermittelt und bewiesen werden.
¶ Der Algorithmus im Detail[3:3]
Die folgenden Pseudocode-Blöcke beinhalten die wesentlichen Bestandteile des PNS-Algorithmus, und sind aus dem Paper übernommen.
¶ Proof-/Disproof-Zahlen
Der folgende Pseudocode formalisiert die oben beschriebenen Regeln zur Berechnung der Proof-/Disproof-Zahlen für einen Knoten J. Der Wert v entspricht dabei der zu beweisenden Annahme (z.B. Sieg oder ein konkreter Punkwert).
if is_a_terminal_node(J) then
if evaluation_value_known then
if value(J) >= v then
proof(J) := 0
disproof(J) := infinity
else
proof(J) := infinity
disproof(J) := 0
endif
else
proof(J) := 1
disproof(J) := 1
endif
else if is_an_internal_node(J) then
if max_node(J) then
proof(J) := min of { proof(j) : j in childs(J) }
disproof(J) := sum of { disproof(j) : j in childs(J) }
else
proof(J) := sum of { proof(j) : j in childs(J) }
disproof(J) := min of { disproof(j) : j in childs(J) }
endif
endif
¶ den vielversprechendsten Knoten auswählen
Diese Funktion wählt den vielversprechendsten Knoten aus, indem sie vom Wurzelknoten J aus dem Pfad des geringsten Beweisaufwands anhand der Proof-/Disproof-Zahlen folgt.
Da bei gleicher Proof-/Disproof-Zahl kein Unterschied zwischen den verschiedenen Knoten ausgemacht werden kann, wird in diesem Fall das linkeste Kind (leftmost child) des Knotens ausgewählt.
function select_most_proving_node(J)
begin
while is_an_internal_node(J) do
if max_node(J) then
J := leftmost_child_with_equal_proof_number(J)
else
J := leftmost_child_with_equal_disproof_number(J)
endif
done
return J
end
¶ Proof-/Disproof-Zahlen aktualisieren
Nachdem der vielversprechendste Knoten expandiert wurde, werden die (Dis-)Proof-Zahlen seiner Vorfahren durch diese Funktion aktualisiert.
procedure update_proof_numbers(J)
begin
while J != NIL do
if max_node(J) then
proof(J) := min of { proof(j) : j in childs(J) }
disproof(J) := sum of { disproof(j) : j in childs(J) }
else
proof(J) := sum of { proof(j) : j in childs(J) }
disproof(J) := min of { disproof(j) : j in childs(J) }
endif
J := parent(J)
done
end
¶ PN-Search für zweiwertige Spielbäume
Dies ist die Hauptschleife des Algorithmus für zweiwertige Probleme. Sie startet mit einem Baum, der nur aus dem Wurzelknoten besteht.
In jeder Iteration wird der vielversprechendste Knoten ausgewählt und expandiert, und die (Dis-)Proof-Zahlen werden aktualisiert. Die Schleife endet, sobald die Annahme für den Wurzelknoten bewiesen (proof(root) == 0) oder widerlegt (disproof(root) == 0) ist.
function two_valued_pn_search
begin
create_root(root)
while proof(root) != 0 and disproof(root) != 0 do
most_proving := select_most_proving_node(root)
expand_node(most_proving)
update_proof_numbers(most_proving)
done
if proof(root) = 0 then
return v
else
return not v
endif
end
¶ PN-Search für mehrwertige Spielbäume
Der Pseudocode für mehrwertige Spiele implementiert eine binäre Suche, um den exakten Spielwert zu finden. Dabei wird der two_valued_pn_search-Algorithmus wiederholt aufgerufen, um die untere (lower) und obere (upper) Schranke des möglichen Spielwerts schrittweise einzugrenzen, bis der exakte Wert feststeht.
function multi_valued_pn_search
begin
while lower < upper do
v := integer_greater_or_equal((lower + upper) / 2)
if two_valued_pn_search = v then
lower := v
else
upper := v - 1
endif
done
return upper
end
¶ Optimierungen[3:4]
Proof-Number Search behält für den Suchprozess, den gesamten Suchbaum im Speicher, da jeder Knoten, der noch nicht expandiert wurde, als vielversprechendster Knoten ausgewählt wurde. In dieser Hinsicht sind depth-first Algorithmen wie die α-β-Suche effizienter.
Die folgenden Techniken können jedoch dabei helfen, den Speicherbedarf zu reduzieren:
- DeleteSolvedSubtrees: Sobald ein Teilbaum vollständig bewiesen oder widerlegt wurde, kann er entfernt werden.
- DeleteLeastProving: Sollte der Speicher knapp werden, kann gezielt ein Knoten gelöscht werden, der mit hoher Wahrscheinlichkeit nicht zur Beweisführung beiträgt (der least-proving node).
Zudem kann die Laufzeit durch folgende kleine Optimierungen verbessert werden:
- Nachdem der vielversprechendste Knoten expandiert wurde, müssen nicht die Proof-/Disproof-Zahlen aller Vorgängerknoten aktualisiert werden. Es reicht aus, solange zu aktualisieren, bis bei einem Knoten keine Veränderung mehr auftritt. Dann können sich auch die jeweiligen Werte der weiteren Vorgänger nicht mehr ändern.
- Aufbauend auf der Beobachtung von gerade lässt sich eine weitere Optimierung durchführen: Ist
vder erste Knoten, bei dem sich die Proof-/Disproof-Werte nicht mehr ändern, liegt der nächste vielversprechendste Knoten wieder im Teilbaum vonv, da sich die Werte der Knoten außerhalb dieses Teilbaums nicht verändert haben. Die Suche nach dem nächsten vielversprechendsten Knoten kann also beivgestartet werden. - Während die Proof-/Disproof-Zahlen für einen Knoten aktualisiert werden, kann bereits der vielversprechendste Knoten für diesen Teilbaum gespeichert werden. Dadurch kann man sich den extra Durchlauf zur Bestimmung sparen.
¶ Evaluation[3:5]
Im Vergleich zu α-β-Suche ist die Anzahl der besuchten Knoten bei PN-Search deutlich kleiner, wenn der Suchbaum eine bestimmte Größe erreicht.
Der Hauptnachteil liegt im erhöhten Speicherbedarf, da der ganze Suchbaum im Speicher gehalten werden muss. Das kann bei großen Suchbäumen problematisch sein.
¶ Weiterführend
Proof-Number Search bildet die Grundlage für einige erweiterte Algorithmen. In diesem Wiki sind dazu die Varianten df-pn und WPNS zu finden.
¶ Bildquellen
Abb. 1: übernommen aus [3:6] (Figure 1)
Abb. 2: übernommen aus [3:7] (Figure 5)
¶ Literaturliste
McAllester, D. A. (1985). A new procedure for growing mini-max trees (Technical Report). MIT Artificial Intelligence Laboratory. ↩︎
McAllester, D. A. (1988). Conspiracy numbers for min-max search. Artificial Intelligence, 35(3), 287-310. ↩︎
Allis, L. V., Van Der Meulen, M., & Van Den Herik, H. J. (1994). Proof-number search. Artificial Intelligence, 66(1), 91-124. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎