¶ Puzzle

Ein Puzzle ist ein mechanisches Rätsel. Ziel ist es eine Menge von Puzzleteilen zu einem Gesamtgefüge zusammenzusetzen. Oft müssen Teile so arrangiert werden, dass dabei ein Bild entsteht.
Neben dem Begriff Puzzle ist auch der Englische Begriff Jigsaw Puzzle geläufig.
In diesem Artikel soll vor allem auf die Verwendung von Computeralgorithmen zur Lösung von Puzzlespielen eingegangen werden.
¶ Eine kurze Geschichte der Puzzlespiele
Die Erfindung von Puzzlespielen ist schwer eindeutig zu verfolgen, jedoch wird meist
John Spilsbury als erfinder des Puzzles betrachtet [1]. Spilsbury schuf 1766 sein Puzzle aus einer Landkarte von Großbritannien, welche er auf ein Holzbrett klebte und entlang von
geographischen Grenzen zersägte. Das ist auch der Ursprung der englischen Bezeichnung "jigsaw puzzle". [1:1]
Ziel von Spielsbury's Puzzle war es, die Karte wieder korrekt zu rekonstruieren. Somit sollte es als Lernmaterial zur Vermittlung von Geographie-Kenntnissen dienen.[1:2] Bilder wurden allerdings erst in den 1860er und 70er Jahren verwendet. [1:3]
Die Suche nach effizienten Algorithmen zur Lösung von Puzzlespielen fing 1964 mit der Arbeit von Freeman und Garder an.[2] Im Gegensatz zu den meisten modernen Ansätzen benutze der von Freeman und Garder vorgeschlagene Algorithmus nur die Form der Puzzleteile und keine Bildinformation.
¶ Algorithmen für Puzzle
Der erste Lösungsansatz für Puzzles wurde 1964 von Freeman und Garder [2:1] vorgestellt. Neben diesem präsentierten Freeman und Garder auch einen ersten Formalisierungsansatz zur Untersuchung von Puzzlespielen. Altman [3] konnte in der Folge zeigen, dass das von Freeman und Garder beschriebene Puzzle-Problem NP-vollständig ist. Bei dem von Freeman und Garder untersuchten Puzzle-Problem handelte es sich aber um das sogenannte "apictorial" Puzzle. Also eines bei dem die Aufgabe darin besteht Puzzleteile nach der Form der Teile und nicht anhand von Bildinformationen zusammenzusetzen. Die NP-vollständigkeit gilt allerdings auch für Bild-Puzzle. [4].
Erst 1994 benutze zuerst Kosiba sowohl die Form der Teile als auch Bildinformation um das Puzzle-Problem zu behandeln [5] [6]. Neuere Ansätze stammen meist aus Feldern der Computer Grafik und Computer Vision.[7] Im Laufe der Zeit haben sich hier vor allem Greedy-Algorithmen und kombinatorische Strategien zur Lösung von Puzzles herausgebildet [7:1].
Von Gallagher wurde 2012 ein Greedy-Algorithmus zur Assemblierung von Puzzles vorgestellt, welcher auf dem Kruskal Algorithmus basierte [6:1]. Auch traf Gallagher die Unterscheidung zwischen Typ-1 und Typ-2 Puzzlespielen. Wobei Typ-1 Puzzle solche sind bei denen die Orientierung (Rotation) der einzelen Puzzleteile bekannt ist. Bei Typ-2 Puzzles dagegen ist auch die Orientierung unbekannt. [6:2] Diese Unterscheidung wurde allerdings auch schon in früheren Arbeiten getroffen [2:2] (wenn auch die Bezeichnung Typ-1 und Typ-2 auf Gallagher zurückgeht).
Sholomon untersuchte 2013 die Verwendung von genetischen Algorithmen um Puzzlespiele zu lösen.[8] Im Gegensatz zu Gallagher's Ansatz handelt es sich hierbei um einen global kombinatorischen Versuch [7:2].
Die Verwandtschaft des Puzzle-Problems mit anderen Problemen aus dem Bereich von Computer Vision, wie zum Beispiel SfM (Structure from Motion) und SLAM, hat ebenfalls Lösungsansätze inspiriert [7:3]. So schlugen zum Beispiel Son et al. die Verwendung von Loop Constraints vor[9].
Ein Versuch die Vorteile von Greedy-Strategien und globalen Strategien zu Kombinieren wurde von Yu et al. im Jahre 2015 unternommen.[7:4] In diesem Artikel wurde die Verwendung von linearer Programmierung (LP) zur Lösung von Puzzles untersucht.
¶ Formale Beschreibung des Puzzle-Problems
Das Puzzle-Problem kann allgemein wie folgt beschrieben werden. Gegeben ist eine Menge von Puzzleteilen . Das Ziel ist es eine Zuordung von Puzzleteilen zu Koordinaten zu finden so dass das Puzzle "korrekt" rekonstruiert ist und die Koordinaten auf einem ganzzahligen Raster liegen. Also gilt . [7:5]
Es ist anzumerken, dass es sich bei der oben gegebenen Beschreibung vor allem um das Puzzle-Problem mit rechteckigen Puzzleteilen handelt. In der Literatur sind auch andere Formulierungen gebräuchlich für z.B. nicht rechteckige Puzzleteile [2:3][5:1] [3:1]. Andere Puzzle-Probleme sind jedoch mehr oder weniger gleichwertig und gleich schwer. Ein Algorithmus der das oben beschriebene Puzzle-Problem löst lässt sich auch auf andere Arten von Puzzles anwenden [4:1].
¶ Freeman und Garders Ansatz [2:4]
Freeman und Garder präsentierten den ersten algorithmischen Ansatz um Puzzles zu lösen. Der von Freeman und Garder vorgeschlagene Algorithmus benutzte jedoch nur die Form der Puzzleteile als Information. Bei dieser Variante des Puzzle-Problems wird auch von "apictorial" Puzzles bzw. "apictorial jigsaw puzzle" gesprochen.
Zuerst wurden paarweise Matches, basierend auf der Form der Puzzleteile gebildet. Diese wurden dann nach und nach zusammengefügt. [2:5] Damit stellt der Algorithmus von Freeman und Garder einen frühen Greedy-Algorithmus für Puzzle dar. Auch heutige Algorithmen folgen dem groben Muster von Freeman und Garder. Viele Solver lassen sich grob durch eine Strategie für paarweise Matches die dann assembliert werden, charakterisieren [7:6][6:3].
¶ MST Assemblierung
Gallagher schlug 2012 eine Variante von Kruskal's Algorithmus vor um Puzzleteile zusammenzusetzen.[6:4] Die Grundlegende Idee ist, ein Puzzle als Graph zu betrachten indem jedes Puzzleteil ein Knoten ist, welcher über eine Kante mit jedem anderen Puzzleteil verbunden ist. Die Gewichtung der Kante entspricht hierbei der Kompatibilität zweier Puzzleteile. Der MST des Graph entspricht hierbei einer Lösung des Puzzle-Problems mit minimalen Kosten.
Kruskal's Algorithmus muss jedoch weiter modifiziert werden, da die Puzzleteile im fertigen Puzzle nicht überlappen dürfen. Um diese Bedingung abzubilden, schlug Gallagher eine modifizierte Variante des Algorithmus vor. [6:5][7:7]
Der Artikel von Gallagher wurde neben den Algorithmischen Aspekten vor allem auch wegen der Einführung der MGC Heuristik zitiert [7:8].
¶ Genetische Programmierung
Auch die Möglichkeit von genetischen Algorithmen zur Lösung von Puzzles wurde untersucht. Sholomon et al. schlugen einen genetischen Algorithmus für sehr große Puzzle vor [8:1]. Chromosome repräsentieren hierbei eine komplette Konfiguration des Puzzles. Die Fitness wurde basierend auf der Kompatibilität von Puzzleteilen mit ihren Nachbarn bestimmt.
Die Herausforderung bei genetischen Algorithmen bestand vor allem darin Crossover sinnvoll zu definieren. Da naives Crossover zu duplizierten oder fehlenden Teilen führen würde. Die von Sholomon et al. vorgeschlagene Lösung war sogenanntes "kernel-growing" [8:2]. Es wird hier zufällig ein Teil ausgewählt (der Kernel), dieses wird nach und nach durch Nachbarn erweitert, die idealerweise Nachbarn des gleichen Teils bei den Eltern-Chromosomen ist. Damit wird das Duplizieren oder Fehlen von Teilen ausgeschlossen und jede Generation bleibt gültig.
¶ Lösung mittels Linearer Programmierung [7:9]
Im folgenden soll der Ansatz von Yu et al. aus dem Jahre 2015, welcher in dem Artikel "Solving Jigsaw Puzzles with Linear Programming" vorgestellt wurde, thematisiert werden. Dieser benutzt lineare Programmierung (LP) um effizient ein Bild zu rekonstruieren.
¶ Informelle Beschreibung
Wie bei anderen Algorithmen [2:6] [6:6], beginnt der Algorithmus von Yu et al. zunächst damit alle Puzzleteile paarweise entlang aller möglichen Kanten zu vergleichen. Die Idee ist es durch auswählen der korrekten Nachbarteile das Puzzle zu rekonstruieren. Wohingegen jedoch beispielsweise Greedy-Algorithmen nun versuchen möglichst schnell Puzzleteile zu größeren Stücken zusammenzusetzen [6:7], benutzen Yu et al. iterative LP Optimierungen um Puzzleteilen Koordinaten zuzuordnen. Der Nachteil bei Greedy-Algorithmen besteht meist darin, dass das frühe Festlegen auf womöglich falsche Puzzleteil-Paare dazu führt dass eine globale Lösung nicht gefunden werden kann [7:10]. Ein Hauptziel des LP-Algorithmus bestand darin, den Assemblierungsprozess robuster und weniger Fehleranfällig zu machen.
Koordinaten werden als Unbekannte in einem Gleichungssystem Behandelt, wenn Paare von Puzzleteilen tatsächlich nebeneinander liegen, dann sollten ihre Koordinaten sich um genau unterscheiden. Wenn Puzzleteile jedoch nicht nebeneinander liegen (kein gutes Match sind), dann wird es eine optimalere globale Lösung geben, so dass diese Puzzleteile neben ihren echten Nachbarn liegen. Da hier nun die Platzierung aller Puzzleteile gleichzeitig berücksichtige wird, ist es unwahrscheinlicher, dass unsichere Puzzleteile zu früh platziert werden.
Die Annahme von Yu et al. besteht also darin, dass korrekte lokale Paarungen auch mit dem globalen Arrangement des Puzzles konsistent sind. [7:11]
¶ Formale Beschreibung
¶ Mögliche Kandidaten für Paare

Der Algorithmus beginnt damit alle möglichen Paarungen von benachbarten Puzzleteilen zu bilden. Für ein Puzzle mit Teilen kann ein möglicher Kandidat durch ein 3-Tupel der Form dargestellt werden. Wobei und die Orientierung kodiert. Das Tuple bezeichnet also die Möglichkeit dass Puzzleteil und benachbart an Kante liegen.
Die Menge all dieser Tupel wird Universum genannt [7:12], mit
Zu bemerken ist, dass eine korrekte Lösung des Puzzles vollkommen durch eine Teilmenge von beschrieben wird. Ein Algorithmus der die korrekte Teilmenge findet, löst auch das Puzzle-Problem.
¶ Heuristik
Um zu bewerten wie gut ein Match ist, wird eine Heuristik benötigt. Die von Yu et al. verwendete Heuristik ist die sogenannte Mahalanobis Gradient Compatibility distance (MGC) [7:13][6:8].
Für das berechnen der Kompatibilität von Puzzleteilen basierend auf dem Bildinhalt sind in der Literatur einige Algorithmen bekannt[10]. Eine der einfachsten Methoden, ist sich einfach den Farbunterschied zwischen den Teilen anzusehen. Diese Methode ist jedoch sehr Fehleranfällig [10:1]. Eine bessere Methode ist der MGC score welcher von Gallagher vorgeschlagen wurde [6:9].
Bei MGC wird der Intensitätsgradient betrachtet. Um den MGC score entlang des rechten Bildrands zu bestimmen (Position ), wird folgende Berechnung gemacht. Der Gradient für Teil entlang des rechten Rands (Pixelposition ) und Farbchannel ist definiert als:[6:10][10:2]
Damit kann nun der Gradient vom rechten Bildrand von zum linken Bildrand zu gebildet werden, mit folgender Gleichung [6:11]
Als Maß für die Kompatibilität zweier Puzzleteile wird nun die Mahalanobis Distanz verwendet. Im Gegensatz zur euklidischen Distanz, korrigiert die Mahalanobis Distanz für Kovarianzen zwischen den einzelnen Farbkanälen im Bild. [6:12]
Wobei es sich bei um das Mittel der Verteilung der Gradienten handelt. Also
und bei um eine 3x3 Kovarianz-Matrix. Im allgemeinen ist nicht symmetrisch. Deshalb wird von Gallagher auch ein symmetrisches Maß vorgeschlagen[6:13]. Da dieses für die Lösung von Puzzles mittels linearer Programmierung jedoch nicht weiter verwendet wird, soll diese Metrik nicht erörtert werden.
Als Maß wie gut Kandidaten sind (und wie stark diese damit die Kostenfunktion beeinflussen sollen) wird von Yu et al. auch eine heuristische Gewichtung verwendet. Diese kann wie folgt berechnet werden. [7:14]
¶ Constraints
Um nun das Puzzle-Problem als geometrisches Constraint-Satisfaction-Problem, welches mit LP behandelt werden kann, zu formulieren, benutzen Yu et al. so genannte "matching constraints"[7:15]. Die zentrale Idee der matching constraints ist, wenn zwei Puzzleteile tatsächliche Matches sind oder anders formuliert wenn ein Kandidaten-Tupel Teil der Lösung ist, dann sollten ihre Koordinaten sich genau um den Wert unterscheiden. Damit kann der folgende soll-offset definiert werden, für
und für
¶ LP-Formulierung
Mittels matching constraints und der Heuristik, kann das Puzzle-Problem in folgendes Optimierungsproblem umgewandelt werden.
Zu minimieren ist die Kostenfunktion
mit Bedingung
Zuerst sollte bemerkt werden, dass die Zielfunktion symmetrisch bzgl. und ist. Der Übersichtlichkeit wegen, werden daher von Yu et al. alle Formeln nur in Bezug auf gegeben, da analog definiert ist.[7:16] Auch in diesem Artikel werden in der Folge Formeln nur in Bezug auf erläutert.
Da die bisherige Formulierung noch nicht linear ist, werden eine Reihe von Umformungen vorgenommen.
- Relaxierung der Integer Bedingung:
Damit kann gelten. Es muss nicht mehr zwingend gelten.
- Relaxierung der L0-Norm:
Ein weiteres Problem ist die L0-Norm. Diese ist genau dann , wenn , sonst ist sie . Damit ist diese Norm formal für das Puzzle-Problem geeignet, aber nicht für die LP-Formulierung. Zuerst wird diese zur L1-Norm (Betrag) relaxiert.
- Auflösen des Betrags
Um den Betrag darstellen zu können, wird die Hilfsvariable eingeführt ( kann analog für und aufgestellt werden). Zu bemerken ist, dass wie folgt durch lineare Nebenbedingungen modelliert werden kann:
Damit kann der Betrag in der Kostenfunktion durch die Hilfsvariablen ersetzt werden. Durch Nebenbedingungen wird dann der Betrag "simuliert".
- Einführung der active selection
Ein neues Problem, welches durch die Relaxierung der L0-Norm entstanden ist, ist dass nun falsche Kandidaten in der Kostenfunktion proportional übergewichtet werden. Daher kann nichtmehr über ganz optimiert werden.
Ein weiterer Grund warum nicht über ganz optimiert werden kann, ist auch, dass das Puzzle-Problem NP-schwer ist. Da allerdings das Optimierungsproblem auch das Puzzle-Problem löst, muss eine andere Formulierung gewählt werden.
Die Lösung, ist die LP-Optimierung iterative auszuführen. Dazu wird in jeder Iteration eine Teilmenge benutzt.[7:17] Diese Teilmenge wird
von Yu et al. active selection genannt. Die active selection wird wie folgt berechent[7:18]
Wobei mittels MGC berechnet wird. Mit den gefundenen Koordinaten (durch LP), werden danach die Matches im Universum verbessert. Dies geschieht durch Rejection. Der Prozess wird widerholt für , bis konvergiert.
Mit diesen Umformungen kann nun eine LP-Formulierung des Puzzle-Problems aufgestellt werden.[7:19]
mit Bedingung
Da die Kostenfunktion symmetrisch bzgl. und ist, gilt die analoge Formulierung für .
Nun kann ein beliebiger Algorithmus für LPs verwendet werden um Koordinaten für zu finden (z.B. der Simplex-Algorithmus [11]). Der genaue Algorithmus der von Yu et al. verwendet wird, wird im Artikel nicht genannt. Weitere Forschung könnte hier womöglich die Leistung unterschiedlicher Algorithmen untersuchen. Wahrscheinlich wurde für die Experimente von Yu et al. aber ein optimierter Solver verwendet.
¶ Rejection
Um iterativ die active selection und die Kandidatenmenge, also das Universum, anzupassen, werden unwahrscheinliche Matches aus der Universumsmenge entfernt. Die Idee ist hier, dass wenn Matches in der Lösung vorkommen, sollten sie sich den globalen geometrischen Bedingungen anpassen (Offset von haben). Weicht der Koordinaten-Offset von potentiellen Matches stark vom geforderten Offset ab, wird das Tupel aus der Menge genommen. Damit wird nach jeder Iteration wie folgt berechnet.
mit
wobei mittels der LP Optimierung gefunden werden.
Der Parameter wird von Yu et al. als gewählt[7:20]. Die Auswirkung von unterschiedlichen Werten wird von Yu et al. leider weder empirisch noch analytisch begründet. Weitere Forschung könnte sich auf die Auswirkung dieses Hyperparemters auf z.B. Konvergenz des Algorithmus fokussieren.
¶ Algorithmus
Der folgende Pseudocode gibt einen groben Überblick über die Funktion des Algorithmus.[7:21]
generate pairwise matches U^(0) and A^(0)
solve LP to get x^(0), y^(0)
while not converged do
generate R^(k)
update U^(k)
compute pairwise matches A^(k)
solve x^(k), y^(k)
end
¶ Erweiterung für Typ-2 Puzzle
Der hier vorgestellte Algorithmus kann Problemlos auch auf Typ-2 Puzzle verallgemeinert werden. Die von Yu et al. vorgestellte Methode besteht darin alle Puzzleteile vier mal zu duplizieren (alle Orientierungen), und dann alle vier Typ-1 Puzzle gleichzeitig zu lösen. Weitere Forschung könnte auch womöglich darin bestehen, hier nach Optimierungen zu suchen.
¶ Constraint Variante
Da sich gezeigt hat, dass durch das neue Wählen von oft korrekte Komponenten des Puzzles zerstört werden können, schlagen Yu et al. auch eine Variante des Algorithmus vor. Hier werden zusätzliche Randbedingungen für zusammenhängende Puzzle-Fragmente eingeführt. Durch die neuen Nebenbedingungen müssen, diese Puzzleteile in der selben Position relativ zu Nachbarteilen bleiben.
Yu et al. schlagen darüber hinaus auch einen hybrid Ansatz vor, welcher beide Methoden benutzt und basierend auf der Kostenfunktion die Lösung wählt.
Diese Varianten werden von Yu et al. allerdings nur sehr kurz erklärt. Details zur genauen Implementierung bleiben hier offen. Auch das wäre ein interessanter Punkt für weitere Forschung.
¶ Vergleich mit anderen Algorithmen
Um die Leistung des Algorithmus zu untersuchen wurden mehrere bekannte Datensätze verwendet. Zur Untersuchung der Robustheit des von Yu et al. Vorgestellten Algorithmus mit anderen Algorithmen wurde der MIT datensatz von Cho et al. [12][7:22] verwendet. Die Bilder wurden hierbei mit normal-verteiltem Rauschen überlagert. In der nachfolgenden Abbildung sind die Ergebnisse dargestellt. Wie zu erkennen ist, ist der Ansatz von Yu et al. weitaus stabiler in Anwesenheit von Rauschen. Die Algorithmen mit denen der LP Ansatz verglichen werden ist einmal der Algorithmus, welcher von Gallagher vorgestellt wurde (Ansatz basierend auf Kruskal's Algorithmus)[6:14]. Des weiteren wird die Robustheit mit dem Algorithmus von Son et al., welcher Loop-Constraints verwendet, verglichen.[9:1][7:23]
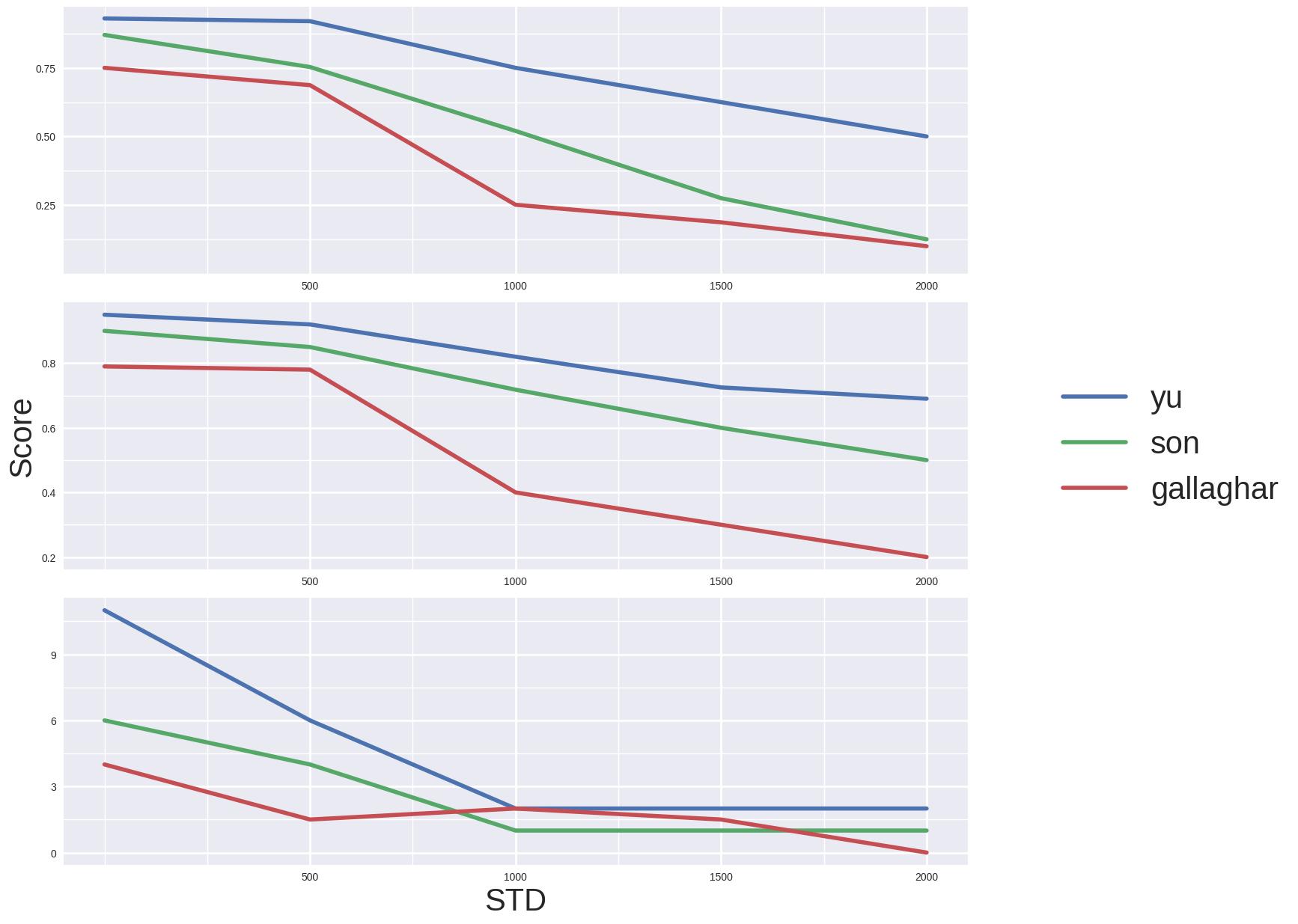
¶ Laufzeitanalyse
Die Laufzeit des Algorithmus wird nicht analytisch von Yu et al. untersucht. Als Bottleneck identifizieren Yu et al. allerdings den matching-Algorithmus von Gallagher [7:24][6:15]. Es wird von den Autoren Spekuliert, dass der LP Ansatz meistens eine in etwa quadratische Laufzeitkomplexität aufweist. Also mit skaliert.
¶ Ausblick
Es ist Yu et. al gelungen einen Ansatz basierend auf linearer Programmierung für das Puzzle-Problem zu entwickeln. Der vorgestellte Algorithmus erreichte dabei state-of-the-art Performance und war kompetitiv mit bereits erprobten Algorithmen.
Ansätze für weitere Forschung, könnten unter anderem praktische Anwendungen des Algorithmus sein. Hier fallen natürlich sofort klassische Problemstellung der Computer Vision und Computer Grafik auf. Neben Rekonstruktions-Aufgaben, wäre die Robotik auch ein viel versprechendes Anwendungsfeld. Besonders für 3D Rekonstruktion bei SLAM oder autonomes Navigieren von Robotern oder Fahrzeugen. Ein Problem des Algorithmus könnte hier jedoch das effiziente Lösen von datenreichen LP-Problemen auf eingebetteten Systemen sein.
Es bleiben auch noch einige theoretische Fragen offen. Wie sollten Parameter wie gewählt werden? Gibt es womöglich bessere mathematische Formulierungen? Eine relevante Frage wäre ob der "Suchbereich" für LP weiter eingeschränkt werden kann. Auch wäre es denkbar, dass durch das erhöhen der Nebenbedingungen (bei der LP-Formulierung), die LP-Optimierung ineffizienter und komplexer wird (da sich womöglich die Anzahl der Kanten des LP-Polyeders erhöht).
Neben der Theorie sollte auch die Auswirkung der Heuristik auf den Algorithmus empirisch untersucht werden. Yu et al. bemerken, dass das Bottleneck des Algorithmus Gallaghers matching ist[7:25]. Es wird aber auch festgestellt, dass der Algorithmus eine höhere Resilienz gegen Noise hat. Damit ergibt sich die Frage, ob eine schlechtere bzw. ungenauere Bewertung mit mehr Noise verwendet werden kann, welche jedoch schneller ist.
¶ Implementierung
Der folgende Python Code gibt einen groben Überblick über eine mögliche Implementierung des von Yu et al. vorgeschlagenen Algorithmus.
def solve(puzzle):
U, D = gen_pairwise_match(puzzle)
A = select_A(U, D).reshape(-1, 4)
weights = compute_weights(A, D)
xy = solve_LP(A, weights)
old_xy = None
while not np.array_equal(old_xy, xy):
U = reject(U, A, xy[:, 0], xy[:, 1])
A = select_A(U, D).reshape(-1, 4)
weights = compute_weights(A, D)
old_xy = xy
xy = solve_LP(A, weights)
positions = []
for i, (x, y) in enumerate(xy):
positions.append((int(x), int(y), i))
piece_order = sorted(positions, key=lambda x: (x[1], x[0]))
return [puzzle[i] for _, _, i in piece_order]
¶ Anwendungen
Jenseits von Puzzles lassen sich Algorithmen für das Lösen von Puzzles auch auf andere Domänen, anwenden. Deever und Gallagher präsentierte 2012 einen Algorithmus zum rekonstruieren von geschredderten Dokumenten, basierend auf Algorithmen für Puzzles[13]. Castañeda et al. haben sich 2011 in einem Artikel mit der Rekonstruktion von Fresken beschäftigt.[14] Auch hier kamen Algorithmen die zuerst für Puzzles entwickelt wurden zum Einsatz. Auch bei anderen Problemen der Archäologie wurden Puzzle Algorithmen verwendet, wie bei der Rekonstruktion zerstörter 3D-Objekte [15][16].
Auch für allgemeine Machine Learning Anwendungen konnte das Puzzle-Problem verwendet werden. Noroozi et al. konnten 2016 demonstrieren, dass das Puzzle-Problem geeignet ist, um unsupervised learning für Object detection zu betreiben [17].
¶ Bildquellen
Abb. 1: Puzzlespiel - Abgerufen von Bild
Abb. 2: historisches Landkarten-Puzzle -Abgerufen von url Bild
Abb. 3: Erstellt mittels LibreOffice - Draw nach Abbildung in [7:26]
Abb. 4: Daten Entnommen aus [7:27]
{kind=link}
¶ Literatur
Raikar, Sanat Pai. "puzzle". Encyclopedia Britannica, 10 Nov. 2022, https://www.britannica.com/topic/puzzle. Accessed 1 January 2026. ↩︎ ↩︎ ↩︎ ↩︎
Freeman, Herbert, and L. Garder. "Apictorial jigsaw puzzles: The computer solution of a problem in pattern recognition." IEEE Transactions on Electronic Computers 2 (2006): 118-127. pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Altman, Tom. "Solving the jigsaw puzzle problem in linear time." Applied Artificial Intelligence an International Journal 3.4 (1989): 453-462. pdf ↩︎ ↩︎
Demaine, Erik D., and Martin L. Demaine. "Jigsaw puzzles, edge matching, and polyomino packing: Connections and complexity." Graphs and Combinatorics 23.Suppl 1 (2007): 195-208. pdf ↩︎ ↩︎
Kosiba, David A., et al. "An automatic jigsaw puzzle solver." Proceedings of 12th International conference on pattern recognition. Vol. 1. IEEE, 1994. pdf ↩︎ ↩︎
Gallagher, Andrew C. "Jigsaw puzzles with pieces of unknown orientation." 2012 IEEE Conference on computer vision and pattern recognition. IEEE, 2012. pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Yu, Rui, Chris Russell, and Lourdes Agapito. "Solving jigsaw puzzles with linear programming." arXiv preprint arXiv:1511.04472 (2015). arxiv pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Sholomon, Dror, Omid David, and Nathan S. Netanyahu. "A genetic algorithm-based solver for very large jigsaw puzzles." Proceedings of the IEEE conference on computer vision and pattern recognition. 2013. pdf arxiv ↩︎ ↩︎ ↩︎
Son, Kilho, James Hays, and David B. Cooper. "Solving square jigsaw puzzles with loop constraints." European conference on computer vision. Cham: Springer International Publishing, 2014. pdf ↩︎ ↩︎
Bartle, Aric, and Tianye Lu. "Assembling Jigsaw Puzzles." pdf ↩︎ ↩︎ ↩︎
Dantzig, George B. "Linear programming." Operations research 50.1 (2002): 42-47. pdf ↩︎
Cho, Taeg Sang, Shai Avidan, and William T. Freeman. "A probabilistic image jigsaw puzzle solver." 2010 IEEE Computer society conference on computer vision and pattern recognition. IEEE, 2010. pdf ↩︎
Deever, Aaron, and Andrew Gallagher. "Semi-automatic assembly of real cross-cut shredded documents." 2012 19Th IEEE international conference on image processing. IEEE, 2012. pdf ↩︎
Castañeda, Antonio García, et al. "Global Consistency in the Automatic Assembly of Fragmented Artefacts." VAST. Vol. 11. 2011. pdf ↩︎
Üçoluk, Göktürk, and I. Hakkı Toroslu. "Automatic reconstruction of broken 3-D surface objects." Computers & Graphics 23.4 (1999): 573-582. pdf ↩︎
Huang, Qi-Xing, et al. "Reassembling fractured objects by geometric matching." ACM Siggraph 2006 papers. 2006. 569-578. pdf ↩︎
Noroozi, Mehdi, and Paolo Favaro. "Unsupervised learning of visual representations by solving jigsaw puzzles." European conference on computer vision. Cham: Springer International Publishing, 2016. pdf arxiv ↩︎