¶ Mastermind
Mastermind ist ein klassisches Codeknacker-Brettspiel aus den 1970er Jahren, bei dem ein Spieler (der Codemaker) einen geheimen Farbcode erstellt und der andere (der Codebreaker) diesen durch logisches Raten ermitteln muss. Das Spielprinzip basiert auf dem älteren Zahlenspiel Bulls and Cows und wurde 1970 vom israelischen Postangestellten Mordecai Meirowitz entwickelt. 1971 erschien Mastermind kommerziell bei Invicta Plastics und erlangte weltweite Popularität.[1] Die Spielmechanik zeichnet sich durch ein Feedbacksystem aus schwarzen und weißen Wertungssteckern aus, über das der Codemaker dem Codebreaker partielle Informationen zu jedem Rateversuch gibt. Trotz der einfachen Regeln erfordert Mastermind deduktives Denken und hat eine lange Forschungstradition in den Bereichen Optimierungsstrategien und Informationstheorie, da effiziente Lösungsalgorithmen für den Codebreaker von großem theoretischem Interesse sind.[2]

¶ Spielprinzip und Ablauf
Mastermind wird mit einem Codebrett, farbigen Code-Pegs und kleinen Schlüssel-Pegs für das Feedback gespielt. Üblicherweise wählt der Codemaker eine geheime Farbkombination aus Pegs (Positionen), wobei jeder Peg in einer von Farben eingefärbt ist. In der klassischen Variante sind und , sodass es mögliche verschiedene Codes gibt. Farben dürfen mehrfach auftreten. Der Code wird verdeckt gesteckt. Der Codebreaker hat nun eine festgelegte Anzahl von Versuchen (typisch 8–12 Runden), um den geheimen Code durch logisches Raten herauszufinden.[1:1]
In jeder Runde legt der Codebreaker einen Rate-Code von Pegs. Anschließend gibt der Codemaker ein zweistufiges Feedback: Er steckt bis zu kleine Wertungsstecker neben den geratenen Code, um die Übereinstimmung mitzuteilen. Ein schwarzer Wertungsstein (in obiger Abbildung rot dargestellt) bedeutet, dass ein Farb-Peg im Rateversuch die richtige Farbe an der richtigen Position getroffen hat. Ein weißer Stein bedeutet, dass ein Peg zwar die richtige Farbe enthält, aber an einer falschen Position steht. Kein Stein wird für völlig falsche Farben vergeben. Die Reihenfolge der Feedback-Steine spielt dabei keine Rolle – es wird nur die Anzahl der schwarzen und weißen Treffer insgesamt zurückgemeldet.
Beispiel: Ist der geheime Code Blau–Blau–Grün–Grün und der Spieler rät Blau–Blau–Blau–Grün, würde der Codemaker drei schwarze Pins (für zwei korrekt platzierte Blau und ein Grün) und keinen weißen Pin vergeben, da der dritte Blau-Peg im Tipp keine zusätzliche teilweise Übereinstimmung liefert. Aus dem Feedback kann der Codebreaker nur schließen, wie viele Pegs richtig sind, jedoch nicht welche – diese indirekte Rückmeldung macht das logische Deduktionsproblem aus. Nach dem Feedback entfernt der Codebreaker alle Code-Kombinationen aus seiner Überlegung, die mit der erhaltenen Antwort unvereinbar wären. Dann erfolgt der nächste Rateversuch. Das Spiel endet, wenn der Codebreaker den geheimen Code exakt errät (Gewinn des Codebreakers) oder die maximal erlaubten Züge ausgeschöpft sind, ohne dass der Code geknackt wurde (Gewinn des Codemakers).[4]
¶ Formale Beschreibung
Ein Mastermind-Code lässt sich formal als -Tupel auffassen, wobei jedes ein Farbwert aus einer Menge von Farben ist. Die Menge aller möglichen Geheimcodes hat somit die Größe (z. B. beim klassischen Mastermind).[1:2] In jeder Runde wählt der Codebreaker einen Tipp aus dem Lösungsraum (anfangs selbst). Der Codemaker gibt daraufhin ein Feedback : Dabei ist die Anzahl richtig positionierter Farben (genaue Treffer) und die Anzahl weiterer vorkommender Farben an falscher Position.[5] Formal lässt sich
definieren. Die Zahl der weißen Treffer ergibt sich aus der Differenz der Farbanzahlüberschneidungen abzüglich der schwarzen:
. (Dies entspricht der Anzahl richtig erratener Farben ungeachtet der Position, abzüglich der bereits als schwarz gewerteten.) Für jede Antwort gilt , , jedoch sind nicht alle Kombinationen davon möglich – z. B. schließen und einander aus. Insgesamt gibt es für einen gegebenen Tipp höchstens verschiedene Feedback-Konstellationen (beim klassischen Mastermind maximal 14). [6]
Die Feedback-Funktion ist wohlgeformt, d. h. wenn zwei mögliche Geheimcodes auf einen gegebenen Tipp dasselbe Feedback liefern (), dann können in der aktuellen Informationslage beide Codes nicht unterschieden werden. Der Informationsgehalt eines Feedbacks entspricht somit einer Partitionierung des Lösungspools: Jeder mögliche Antwortfall definiert eine Teilmenge von Codes, die genau dieses Feedback hervorrufen würden.[2:1] Nach Erhalt des tatsächlichen Feedbacks schränkt der Codebreaker den Suchraum auf die entsprechende Teilmenge ein: . Dieser Eliminierungsprozess wird iterativ fortgeführt, bis (Code eindeutig bestimmt) oder eine vorher definierte Maximalzahl an Versuchen erschöpft ist.[5:1]
¶ Algorithmische Zielgrößen
Informatiker und Mathematiker haben Mastermind als kombinatorisches Suchproblem analysiert, wobei verschiedene Optimierungskriterien für die Rate-Strategie des Codebreakers betrachtet werden:
Worst-Case-Minimierung: Hier zielt der Codebreaker darauf ab, die maximale Anzahl benötigter Züge gegen einen optimal agierenden Codemaker zu minimieren. Diese Strategie entspricht einem Minimax-Ansatz in einem Nullsummenspiel: Der Codemaker wählt im schlimmsten Fall immer den für den Codebreaker ungünstigsten Geheimcode (bzw. antwortet so, dass möglichst viele Kandidaten übrigbleiben). Der Codebreaker versucht demgegenüber Züge zu finden, die das Schlimmstenfalls verbleibende Lösungsmenge so klein wie möglich halten.[1:3] Ein Maß dafür ist die Worst-Case-Suchtiefe einer Strategie, d. h. die maximale Rundenanzahl , die zur Garantie der Lösung für jeden Code benötigt wird.[6:1] Ein Mastermind-Strategiebaum optimalen Worst-Case-Tiefs hat minimal mögliche Tiefe; für die Standardparameter () beträgt diese optimale Worst-Case-Zugzahl 5.[2:2] Die Minimierung des schlimmsten Falls wurde erstmals durch Donald E. Knuth 1976 erreicht, der eine Strategie vorgestellte, die jeden Code in höchstens 5 Zügen findet.[7]
Average-Case-Minimierung: Statt des schlimmstmöglichen wird hier die durchschnittlich benötigte Zuganzahl minimiert, wobei über alle möglichen Codes (oder eine gegebene Verteilung) gemittelt wird.[6:2] Diese Zielgröße ist relevant, wenn der geheime Code als zufällig angenommen wird. Eine Strategie ist durchschnittsoptimal, wenn sie minimal macht. Für das klassische Mastermind mit 1296 Codes liegt das theoretisch minimale Erwartungs- bei Zügen.[1:4] Diese durchschnittlich optimale Strategie wurde 1993 von Koyama und Lai durch exhaustive Suche bestimmt. Interessanterweise benötigt sie in wenigen Fällen einen 6. Zug, ist also nicht worst-case-optimal. Allgemein stehen Worst-Case- und Average-Case-Kriterium oft im Konflikt: Eine Strategie, die im Mittel sehr effizient ist, kann dafür in einzelnen schwierigen Fällen einen Zug mehr benötigen.[1:5]
Informationsgewinn (Entropie): Ein dritter Ansatz bewertet Züge nach ihrem informationstheoretischen Ertrag. Hierbei wird die Unsicherheit über den geheimen Code als Zufallsvariable gemessen, etwa mittels Shannon-Entropie:
Zu Spielbeginn mit Gleichverteilung über Codes gilt Bit. Ein Rateversuch mit erwarteten Rückmeldungen partitioniert in Klassen . Für jeden möglichen Feedback-Ausgang sei die Auftrittswahrscheinlichkeit und die Entropie des verbleibenden Kandidatenraums im Fall dieser Antwort. Der erwartete Informationsgewinn des Zugs beträgt dann .[2:3] Entropiebasierte Strategien wählen den Rateversuch, der maximiert, also die erwartete Posterior-Entropie von minimiert. Intuitiv soll so im Durchschnitt der größtmögliche Fortschritt erzielt werden – selbst, wenn dies gelegentlich zu suboptimalem Worst-Case-Verhalten führt. Der Informationsansatz ist myopisch, da er jeweils nur einen Schritt vorausblickt (1-Step-Lookahead). Dennoch hat sich gezeigt, dass diese Heuristik dem Average-Case-Optimum sehr nahekommt. Azer Bestavros und Ahmed Belal beschrieben 1986 erstmals eine solche Maximalentropie-Strategie und quantifizierten den Effizienzgewinn gegenüber einer rein worst-case-orientierten Suche.[5:2]
Neben diesen Hauptkriterien existieren weitere Heuristiken. Beispielsweise schlug Irving 1979 eine Expected size-Strategie (Erwartungswert der Restkandidatenzahl) vor, und Kooi 2005 eine Most parts-Strategie, die Züge nach maximaler Anzahl nicht-leerer Partitionen bewertet.[5:3] In der Praxis erfordern diese Strategien komplexe Abwägungen, da die Anzahl möglicher Partitionierungen groß ist und eine Vollsuche über alle Strategiebäume für größere schnell unbeherrschbar wird.[1:6][8]
¶ Knuths Minimax-Algorithmus (Worst-Case-Strategie)
Donald Knuth publizierte 1976 eine genaue Methode für den Codebreaker, die garantiert in höchstens 5 Zügen zum Ziel führt.[7:1] Diese Minimax-Strategie optimiert das Worst-Case-Kriterium und dient bis heute als Referenz für Mastermind-Lösungsalgorithmen. Knuths Algorithmus lässt sich folgendermaßen zusammenfassen:
-
Initialisierung: Betrachte die Lösungsmenge {alle Codes}. Wähle einen ersten Tipp, z. B. (für in Zifferndarstellung).
-
Feedback auswerten: Erhalte vom Codemaker die Antwort . Falls (alle Positionen korrekt), ist der Geheimcode gefunden und das Spiel endet.
-
Einschränken: Streiche alle Codekandidaten aus , die nicht das Feedback ergeben würden, wenn der Geheimcode wäre. Formal: . (Damit bleiben nur konsistente Codes übrig.)
-
Nächsten Zug wählen: Für jeden potentiellen Tipp (typischerweise betrachtet man alle Möglichkeiten als nächsten Zug) ermittele den größten Teilmengenumfang, den im schlechtesten Fall übrig ließe:
, wobei alle möglichen Feedbackfälle durchläuft. Wähle einen Zug , der minimiert – also die günstigste schlechteste Rückfallmenge besitzt. Bei Gleichstand wird bevorzugt ein gewählt, das selbst noch in liegt (also ein konsistenter Kandidat). -
Runde fortsetzen: Erhöhe und gehe zurück zu Schritt 2.
Knuths Vorgehen garantiert, dass die Größe des Suchraums im schlechtesten Fall so schnell wie möglich schrumpft. In der Praxis fand Knuth heraus, dass mit obigem Algorithmus für jeder Geheimcode nach spätestens 5 Zügen erraten werden kann. Die durchschnittliche Anzahl erforderlicher Züge liegt dabei (je nach Starttipp) bei etwa 4,4. Der Erfolg dieser Strategie beruht darauf, dass sie die Antworten des Codemakers maximal ausnutzt: Jeder Zug wird so gewählt, dass unabhängig vom Feedback eine möglichst große Eliminierung erfolgt. Die Berechnung ist jedoch aufwendig – pro Zug müssen alle potenziellen Tipps durchsimuliert und bewertet werden, was für größere Werte von und kombinatorisch explodiert. Aus diesem Grund wurden zahlreiche heuristische Varianten und Optimierungen vorgeschlagen (z. B. begrenzte Tiefensuchen, vorsortierte Tippmengen, etc.), die das Prinzip der Worst-Case-Minimierung approximieren.[7:2]
Anmerkung: Knuths Originalalgorithmus erlaubt auch Tipps, die selbst nicht konsistent mit früheren Feedbacks sind (d.h. bewusst falsche Fährten), falls dies die Partitionierung verbessert. Persönliche Untersuchungen haben gezeigt, dass man auch rein konsistent raten kann, dann jedoch u.U. einen 6. Zug benötigt.[8:1] Eine streng fünfzügige Strategie ohne inkonsistente Zwischentipps existiert nicht – die Minimierung des Worst-Case erfordert mitunter einen „Opferzug“ (einen Tipp, der nur der Informationsgewinnung dient, nicht unbedingt selbst noch als Lösung in Frage kommt).
¶ Entropie-basierte Strategien (Average-Case-Optimierung)
Statt auf den schlimmsten Fall optimieren entropie-basierte Verfahren den erwarteten Informationsgewinn pro Zug. Sie wurden erstmals von Bestavros & Belal formal beschrieben.[5:4] Die Idee ist, den nächsten Rateversuch so zu wählen, dass die Ungewissheit über den geheimen Code maximal reduziert wird. Wie oben erläutert, lässt sich der Informationsgewinn eines Zugs in Bits ausdrücken. Alternativ kann man direkt die Shannon-Entropie der Feedback-Verteilung anstreben – beide Ansätze sind äquivalent, da bei anfänglich gleichverteiltem Geheimcode gilt.[2:4] Praktisch berechnet man für jeden möglichen Tipp die Größen der durch induzierten Klassen und deren Wahrscheinlichkeiten . Daraus ergibt sich die Erwartungsentropie . Ein optimaler Zug im entropie-greedy Sinne ist dann , also derjenige mit maximalem erwartetem Informationsgewinn.[6:3] Dieses Kriterium neigt dazu, häufig auftretende Rückmeldungen zu bevorzugen, durch die der Lösungsraum im Mittel stark eingeengt wird, auch wenn ungünstige Sonderfälle etwas größer ausfallen mögen.
Die Entropiestrategie ist eng mit dem Average-Case-Ziel verwandt. Tatsächlich liefert sie in Simulationen eine durchschnittliche Zugzahl von ca. 4,40 bei Codes – nahezu so gut wie das exhaustive Optimum 4,34.[1:7][2:5] Gleichzeitig bleibt der Worst-Case mit 6 Zügen moderat. Bestavros & Belal berichteten, dass ihre MaxEnt-Heuristik im Mittel deutlich weniger Züge benötigt als eine reine Minimax-Strategie. Beispielsweise ergab eine Stichprobe, dass die Worst-Case-Strategie durchschnittlich etwa 4,75 Züge brauchte, während die Entropiestrategie mit ~4,15 Zügen auskam (konkrete Werte hängen vom Starttipp und Implementierungsdetails ab).[5:5] Auch neuere Untersuchungen bestätigen, dass die Entropie-Heuristik die besten existierenden Ein-Zug-Vorausplanungs-Methoden darstellt. Sie steht oft gleichauf mit der sogenannten Most-Parts-Heuristik und übertrifft deutlich einfachere Verfahren wie zufälliges konsistentes Raten.[2:6]
Ein Vorteil der Entropiestrategie ist ihre Konzeption: Sie bietet einen informationstheoretischen Maßstab dafür, wie „gut“ ein Rateversuch ist. Dadurch lässt sich die Strategie auch auf Erweiterungen des Mastermind-Problems anwenden – etwa, wenn unterschiedlich gewichtete Fehlversuche oder probabilistische Elemente ins Spiel kommen. Der Nachteil ist der weiterhin hohe Rechenaufwand: Pro Zug müssen alle potentiellen Tipps ausgewertet werden, ähnlich wie bei Minimax. Daher wurden hybride Ansätze entwickelt, z. B. Evolutionäre Algorithmen, die Entropie als Fitness-Funktion nutzen, um Heuristiken stochastisch zu optimieren.[2:7]
¶ Bayessche Modelle und Mastermind mit Unsicherheit
Die bisher betrachteten Strategien setzen voraus, dass das Feedback immer wahrheitsgetreu ist und der geheime Code unverändert bleibt. In realen Spielen trifft dies zu – der Codemaker hält sich an die Regeln. Interessant wird es jedoch, wenn man Mastermind als Bayessches Inferenzproblem formuliert, etwa für Varianten mit unsicherem Feedback[6:4] oder dynamisch wechselndem Code[5:6] (wie im sogenannten Dynamic Mastermind). In solchen Fällen kann der Codebreaker nicht mit absoluter Sicherheit Kandidaten ausschließen, sondern muss jedem möglichen Code eine a posteriori Wahrscheinlichkeit zuweisen.
Ein Bayessches Modell für Mastermind wurde von Vomlel (2004) beschrieben. Dabei wird ein Netzwerk aus Zufallsvariablen konstruiert, das den verborgenen Code, die getätigten Züge sowie die beobachteten Antworten und gegebenenfalls Rauschvariablen umfasst. Über dieses Netzwerk kann man mit Bayes’ Theorem die Verteilung berechnen und bei jeder neuen Antwort aktualisieren (Belief Update). Konkret gilt für jeden möglichen Code im Pool:
Ohne Rauschen sind entweder 0 oder 1 (Feedback deterministisch korrekt oder nicht), wodurch sich diese Formel auf die Mengeneinschränkung reduziert (wie oben: entweder ist konsistent oder nicht). Liegt jedoch ein Störrauschen vor – z. B. der Codemaker gibt mit gewisser Wahrscheinlichkeit falsche Pins an – so verteilt sich die Posteriorwahrscheinlichkeit auf mehrere Kandidaten. Der Codebreaker erhält dann keinen sicheren Ausschluss mehr, sondern muss Wahrscheinlichkeiten verwalten. Entscheidungsstrategien lassen sich in diesem Rahmen als Nutzenfunktionen formulieren, etwa indem man den erwarteten Informationsgewinn eines Zuges bezüglich der Posterior-Verteilung maximiert (analog zur Entropiestrategie, aber mit nicht-uniformer Verteilung). Auch lässt sich ein Kosten-Faktor für Züge integrieren, um z. B. risikobasierte Strategien zu modellieren.[6:6]
Bayessche Modelle erlauben es, Mastermind-Varianten mit unvollständiger oder fehlerhafter Information zu analysieren – ein Themengebiet, das z.B. in der Künstlichen Intelligenz und kognitiven Forschung (menschliche Fehlertoleranz beim Rätsellösen) von Interesse ist. Allerdings steigt die rechnerische Komplexität durch die Verzweigung der Möglichkeiten stark an. Vomlel zeigte, dass die explizite Konstruktion optimaler Strategiebäume für probabilistisches Mastermind bereits bei kleinen Instanzen schwierig ist. Hier kommen approximative Verfahren oder Monte-Carlo-Simulationen, wie potentiell MCTS zum Einsatz, um Bayes’sche Mastermind-Probleme lösbar zu machen.[6:7]
¶ Vergleich der Strategien und Leistungsmaße
Zur Bewertung verschiedener Lösungsansätze werden meist empirische Kennzahlen herangezogen. Üblich ist insbesondere die Verteilungsfunktion der benötigten Züge für einen vollständigen Durchlauf über alle möglichen Geheimcodes (ECDF: empirical cumulative distribution function). Diese Funktion gibt für jede Zuganzahl an, wie viel Prozent aller Codes mit höchstens Rateversuchen geknackt werden können. Aus ihr lassen sich sowohl Worst-Case (Maximalwert) als auch Durchschnitt und Median ablesen.
Eine typische ECDF für die Standardparameter zeigt z. B., dass Knuths Minimax-Algorithmus 100 % der Codes in Zügen löst (Worst-Case = 5), während eine einfache konsistente Zufallsstrategie bis zu 8 Züge benötigen kann. Gleichzeitig ist bei Minimax über die Hälfte aller Fälle tatsächlich worst-case-kritisch – für 53,6 % der Codes werden volle 5 Züge gebraucht. Demgegenüber schafft die Entropiestrategie einen größeren Teil der Lösungen in 4 Zügen, benötigt aber in seltenen Fällen einen 6. Zug (Worst-Case = 6). Ihre durchschnittliche Zuganzahl liegt mit etwas unter der von Minimax () und deutlich unter der von zufälligem Raten (). Im Median (häufigster Bereich) sind beide Heuristiken ähnlich (), doch Entropie hat den Vorteil einer kleineren Varianz.
Einfügen und Abgleich mit eigenem Diagramm
Die folgende Tabelle vergleicht exemplarisch Performance-Metriken verschiedener Strategien (Minimax wählt hier scheinbar nur mögliche Geheimcodes):[2:8]
| Strategie | Ø Züge (Mean) | Median | Worst-Case |
|---|---|---|---|
| Minimax | 4,479 | 4,473 | 6 Züge |
| Entropy | 4,408 | 4,408 | 6 Züge |
| Most Parts | 4,410 | 4,412 | 7 Züge |
| Expected Size | 4,470 | 4,468 | 7 Züge |
| Zufall (konsist.) | 4,608 | 4,608 | 8 Züge |
(Werte gerundet; Worst-Case-Strategie hier mit fixem Starttipp AABC und daher max. 6 statt 5 Züge)
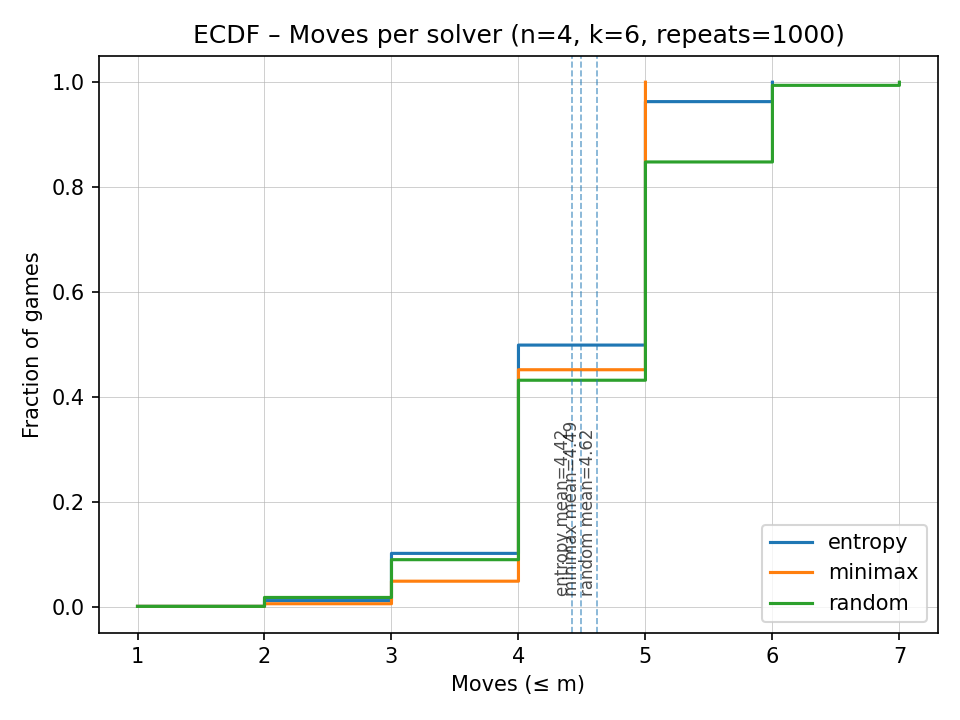
(Benchmark erstellt von Julian Damm)[8:2]
Man erkennt, dass Entropy und Most-Parts im Durchschnitt am besten abschneiden (ca. 4,40 Züge) und keinen Ausreißer über 6 benötigen. Die Worst-Case-optimierte Strategie liegt nur wenig dahinter, garantiert dafür aber einen etwas kleineren Maximalwert (in Knuths Original 5).[7:3] Die zufällige Strategie ist erwartungsgemäß am ineffizientesten. Interessant ist, dass die Worst-Case- und Expected-Case-Heuristiken in obiger Studie ähnlich abschnitten – ein Hinweis darauf, dass eine reine Erwartungswert-Optimierung (Expected Size) ohne Berücksichtigung von Informationsverteilung nicht ausreicht, um Entropie/Most-Parts zu schlagen.[2:9]
Rechenkomplexität: Die algorithmische Schwierigkeit des Mastermind-Codebrechens wächst schnell mit und . Bereits das Mastermind-Satisfiability-Problem (MSP) – zu entscheiden, ob es für eine gegebene Folge von Tipps und Antworten irgendeinen konsistenten Geheimcode gibt – ist NP-vollständig. Ebenso ist die Optimierungsvariante, die minimal benötigten Züge für ein Mastermind-Spiel als Funktion von und zu bestimmen, NP-schwer (verwandt mit dem 3SAT-Problem).[1:8] Diese Resultate erklären, warum eine exakte Lösungsstrategie für allgemeine Parameter vermutlich keinen polynomialen Algorithmus besitzt. Praktisch werden daher heuristische und approximative Methoden eingesetzt, die in akzeptabler Zeit gute (wenn auch nicht immer optimale) Züge finden. Mastermind illustriert damit anschaulich das Spannungsfeld zwischen Exaktheit und Effizienz in kombinatorischen Suchproblemen – und warum informationstheoretische Heuristiken hier so wertvoll sind.
Für eigene Tests und Implementationen zu Mastermind-Algorithmen kann ich mein GitHub-Repository wärmstens empfehlen.[8:3]
¶ Literatur
https://en.wikipedia.org/wiki/Mastermind_(board_game) ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Thomas Philip Runarsson and Juan J. Merelo-Guervós. Adapting heuristic Mastermind strategies to evolutionary algorithms. Nature Inspired Cooperative Strategies for Optimization (NICSO 2010). Berlin, Heidelberg: Springer Berlin Heidelberg, 2010. 255-267.(https://arxiv.org/pdf/0912.2415) pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Eingescannte Anleitung von Hasbro International Inc. (1994) pdf ↩︎
Ahmed Belal, Azer Bestavros. A game of Diagnosis Strategies. (1986). pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Jirı Vomlel. Bayesian networks in mastermind. Proceedings of the 7th Czech-Japan Seminar. 2004. pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Donald E. Knuth. The computer as Master Mind. J. Recreational Mathematics, Vol. 9(1), 1976-77 pdf ↩︎ ↩︎ ↩︎ ↩︎
Repository von Julian Damm, in dem einige Algorithmen im Spiel Mastermind gegeneinander getestet wurden. GitHub ↩︎ ↩︎ ↩︎ ↩︎
{kind=link}