¶ Einleitung

Rush Hour ist ein mechanische Schiebepuzzle, das ursprünglich in den 1970er Jahren von Nob Yoshigahara entwickelt wurde und erstmals 1996 in den USA durch ThinkFun in den Verkauf gebracht wurde[1]. Das Spiel nimmt Inspiration von einem Verkehrsstau, welcher auf einem quadratischen Gitter simuliert wird. Hierbei besteht das Ziel, ein spezifisches rotes Auto durch geschicktes Verschieben anderer Fahrzeuge aus dem Stau heraus zu manövrieren. In dem original Spiel werden 40 Startkonfigurationen der verschiedenen Fahrzeuge auf Karten detailliert, welche in Schwierigkeitsgraden von Anfänger bis Experte untergliedert sind[1:1].
Obwohl es viele verschiedene Lösungsansätze für das Puzzle gibt, fokussiert sich dieser Artikel auf die zwei deklarativen Modellierungen des Puzzles, Constraint Programming und Answer Set Programming, welche im Paper [2] von Cian et al. vorgestellt wurden. Dafür wird erst ein Grundwissen über Rush Hour aufgebaut. Darauf basierend werden die Modellierungen genau erklärt und schlussendlich die experimentellen Ergebnisse des Papers vorgestellt.
¶ Spielregeln und Formalisierung
Das klassische Rush Hour wird auf einem -Gitter gespielt. Auf diesem Spielfeld befinden sich verschiedene Fahrzeuge, die festen Typen zugeordnet sind: Autos (Länge 2) und LKWs (Länge 3). Jedes Fahrzeug hat eine feste Ausrichtung (horizontal oder vertikal) und kann sich nur entlang dieser Richtung vorwärts oder rückwärts bewegen. Seitliche Bewegungen sind nicht erlaubt.
Das Ziel des Spiels ist es, das rote Auto durch den einzigen Ausgang des Spielfelds zu manövrieren. Dafür muss das Auto auch auf der korrekten Zeile oder Spalte in der korrekten Orientation stehen.
Dabei gelten folgende Restriktionen für alle Bewegungen:
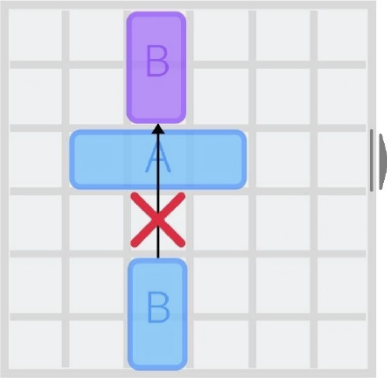
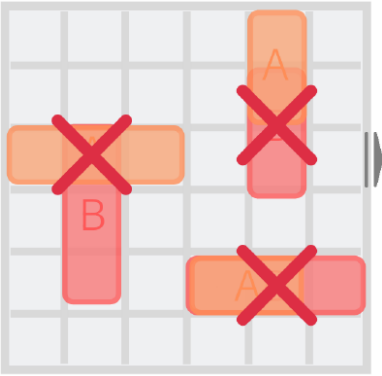
- Kein Überspringen: Fahrzeuge können nicht über andere Fahrzeuge springen (Abb.2 [2:1]).
- Keine Kollisionen: Ein Fahrzeug darf nicht auf ein Feld bewegt werden, das bereits von einem anderen Fahrzeug besetzt ist (Abb. 3 [2:2]).
- Spielfeldgrenzen: Fahrzeuge dürfen das Gitter nicht verlassen. Die einzige Ausnahme bildet das rote Auto, welches das Gitter durch den Ausgang verlassen darf
¶ Mathematische Formalisierung [2:3]
Um Herangehensweisen zu ermöglichen und das Puzzle für beliebige Gittergrößen zu verallgemeinern, wird das Generalized Rush Hour (GRH) Problem formal definiert.
Ein Spielbrett der Größe wird als Teilmenge der kartesischen Ebene definiert, bestehend aus einer Menge von Punkten . Hierbei repräsentiert das untere linke Feld.
Eine Garage ist die Menge der verfügbaren Fahrzeuge, definiert als , wobei Fahrzeug-Index und Größe ein Paar bilden, wobei . Es wird auch die Funktion definiert, welche die Größe eines Fahrzeugs zurückgibt. Die Position eines Fahrzeugs ist eindeutig durch die Koordinaten seiner Front und seiner Orientierung bestimmt.
Eine Allokation ist eine Menge von Tripletts , wobei die Platzierung von Fahrzeug beschreibt. Eine Allokation ist gültig, wenn alle Fahrzeugteile auf dem Gitter liegen und sich keine Fahrzeuge überlappen.
Somit können wir eine GRH-Instanz durch das Tupel , wobei die Brettgröße, den Ausgang, die Garage und die Allokation des Initialzustand darstellen. Es wird angenommen, dass das rote Auto identifiziert. Letztendlich kann es zu einer solchen Instanz eine Lösungssequenz der Länge geben, welche eine Sequenz von Zügen repräsentiert, die so transformieren, sodass das rote Fahrzeug die Position belegt und korrekt ausgerichtet ist, um das Brett zu verlassen. Damit eine Lösung existieren kann, muss die Orientierung von zur Position des Ausgangs passen (z. B. falls ).
¶ Komplexität
Während das Spiel auf einem festen Brett einen endlichen Zustandsraum besitzt, haben Flake und Baum für GRH-Instanzen auf Gittern bewiesen, dass es PSPACE-vollständig ist[3]. In ihrem Paper zeigen sie, wie sich logische Schaltkreise durch Fahrzeugkonstellationen simulieren lassen, was belegt, dass die Berechnung einer Lösung mindestens so speicheraufwendig ist wie die schwierigsten Probleme, die mit polynomialem Platz lösbar sind.
¶ Deklarative Lösungsansätze
In ihrem Paper stellen Cian et al. zwei deklarative Lösungsansätze vor, einmal mit Constraint Programming in der Modellierungssprache MiniZinc und dem Solver Chuffed, und zum anderen mit Answer Set Programming mit den Solvern clingo und DLV. Obwohl das zuvor definierte GRH-Problem theoretisch beliebige Gittergrößen zulässt, fokussiert sich die konkrete Implementierung des Papers auf das klassische Spielfeld () mit festen Ausgang [2:4].
¶ Modellierung mit Constraint Programming (CP)[2:5]
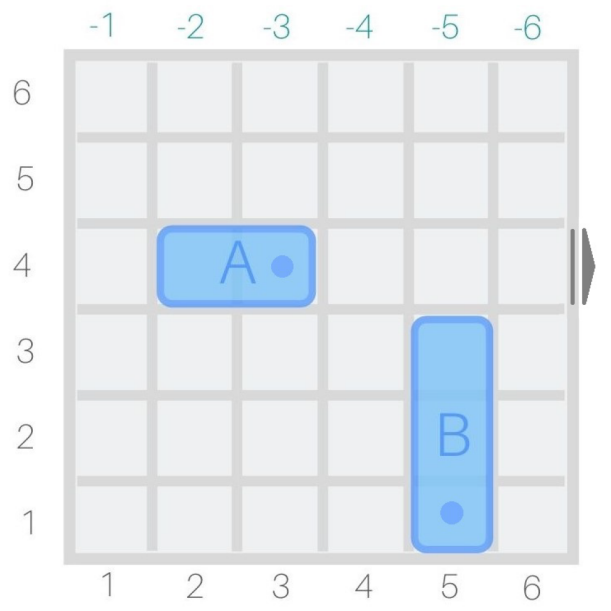
Abb. 4 Beispiel: , , .
Die Modellierung beginnt mit der Repräsentation des Zustandsraums mithilfe eines fahrzeugbasierten Ansatzes, welcher für jeden Zustand nur die Fahrzeuge und nicht das gesamte Spielbrett speichert. Damit wird Speicherplatz gespart und die Modellierung der Zustandsübergänge erleichtert, da sich pro Zeitschritt nur ein Fahrzeug ändert.
Für jedes der Fahrzeuge werden folgende statische Werte in Arrays gespeichert:
- : Die Länge des Fahrzeugs .
- : Dieser Parameter speichert sowohl die Orientierung als auch die fixierte Koordinate.
- Ist , ist das Fahrzeug horizontal ausgerichtet hat ein konstantes .
- Ist , ist das Fahrzeug vertikal ausgerichtet und hat ein konstantes .
- : Die initiale Koordinate des Fahrzeugs, die sich ändern lässt ( für horizontale, für vertikale Fahrzeuge). Hier wird immer die kleinste Koordinate gespeichert (siehe Abb. 4).
Die dynamischen Entscheidungsvariablen, welche die Lösungssequenz mit Zeitschritten bilden (), sind die folgenden zwei Matrizen:
- : Die kleinste Koordinate von Fahrzeug zum Zeitpunkt .
- : Die Bewegung von Fahrzeug zum Zeitpunkt ( falls Stillstand, sonst eine Verschiebung um Felder.
¶ Constraints
Jetzt müssen durch das Modell nur noch eine Reihe von Constraints erstellt werden. Die folgenden Constraints sind in MiniZinc geschrieben, wobei /\ die logische Konjunktion ist und \/ die logische Disjunktion:
- Initialzustand und Ziel:
Zu Beginn () müssen alle Fahrzeuge an ihren Startpositionen stehen (forall(v in 1..r) (pos[v, 1] = initial[v])). Das Ziel ist erreicht, wenn das rote Auto (Index 1) zum Endzeitpunkt die Position vor dem Ausgang (Spalte 5 bei einem Feld mit Ausgang rechts) erreicht hat (pos[1, t] = 5) - Spielfeldgrenzen:
Fahrzeuge dürfen zu keinem Zeitpunkt über den Rand hinausragen ( wird durch den Definitionsbereich garantiert):
forall(v in 1..vehicles, s in 1..steps) (pos[v,s] + size[v] - 1 <= 6) - Keine überschneidende Fahrzeuge:
Zwei Fahrzeuge dürfen sich zum gleichen Zeitpunkt nicht überschneiden. Hierbei werden zwei Fälle unterschieden, nämlich falls zwei Fahrzeuge die selbe Orientierung haben, und falls nicht. Falls sie die selbe Orientierung haben und in derselben Zeile oder Spalte liegen, muss eines vollständig vor oder hinter dem anderen liegen, sonst müssen kreuzende horizontale () und vertikale () Fahrzeuge ausgeschlossen werden:
# Fahrzeuge, welche in derselben Zeile oder Spalte sind, und parallel zueinander sind
forall(v1, v2 in 1..r, s in 1..t where (v1 < v2 /\ versus[v1] = versus[v2]))
(pos[v1,s] + size[v1] - 1 < pos[v2,s] \/
pos[v2,s] + size[v2] - 1 < pos[v1,s]);
# Fahrzeuge, welche orthogonal zueinander sind und sich kreuzen können
forall(v1, v2 in 1..r, s in 1..t where (versus[v1] > 0 /\ versus[v2] < 0))
(not (pos[v1,s] <= -versus[v2] /\
-versus[v2] <= pos[v1,s] + size[v1] - 1 /\
pos[v2,s] <= versus[v1] /\
versus[v1] <= pos[v2,s] + size[v2] - 1));
- Bewegungen
Pro Zeitschritt darf sich exakt ein Fahrzeug bewegen. Dies wird erzwungen, indem die Summe der booleschen Ausdrücke für eine Bewegung genau 1 ergeben muss:forall(s in 1..t-1) (sum(v in 1..r) (move[v,s] != 0) = 1)
Die Position im nächsten Zeitschritt ergibt sich aus der aktuellen Position und der Bewegung:
forall(v in 1..r, s in 1..t-1) (pos[v,s+1] = pos[v,s] + move[v,s]); - Verbot von Sprüngen
Ein weiteres Problem, welches wir betrachten müssen, sind Sprünge von Fahrzeugen über andere in einem Zeitschritt. Es muss hier wieder in Fälle aufgeteilt werden. Bei Fahrzeugen, die Parallel sind, muss , welches vor ist, nach einem Zeitschritt auch noch vor sein (und umgekehrt). Bei Fahrzeugen, welche Orthogonal zueinander sind, darf ein vertikales Fahrzeug , welches die Fahrbahn eines horizontalen Fahrzeugs blockiert, nicht übersprungen werden. darf also seine Position relativ zur Blockade nicht ändern, solange im Weg steht. Dies wird in zwei Constraints aufgeteilt, mit einem Constraint für vertikale und einem Constraint für horizontale Hindernisse. So sieht das formal aus:
# Parallele Fahrzeuge
forall(s in 1..t-1, v1, v2 in 1..r where ((v1 < v2) /\ versus[v1] = versus[v2]))
(not (pos[v1,s] <= pos[v2,s] /\ pos[v1,s+1] > pos[v2,s+1]) /\
not (pos[v2,s] <= pos[v1,s] /\ pos[v2,s+1] > pos[v1,s+1]));
# Orthogonale Fahrzeuge (vertikales Hindernis blockiert horizontales Fahrzeug)
forall(s in 1..t-1, v1, v2 in 1..r where (versus[v1] < 0 /\ versus[v2] > 0))
((pos[v2,s] <= -versus[v1] /\ -versus[v1] <= pos[v2,s] + size[v2] - 1)
-> (pos[v1,s] < versus[v2] -> pos[v1,s+1] < versus[v2]) /\
(pos[v1,s] > versus[v2] -> pos[v1,s+1] > versus[v2]));
# Orthogonale Fahrzeuge (horizontales Hindernis blockiert vertikales Fahrzeug)
forall(s in 1..t-1, v1, v2 in 1..r where (versus[v1] > 0 /\ versus[v2] < 0))
((pos[v2,s] <= versus[v1] /\ versus[v1] <= pos[v2,s] + size[v2] - 1)
-> (pos[v1,s] < -versus[v2] -> pos[v1,s+1] < -versus[v2]) /\
(pos[v1,s] > -versus[v2] -> pos[v1,s+1] > -versus[v2]));
- Symmetriebrechung
Letztendlich wird zur Optimierung der Laufzeit und reduktion des Suchraums eine Symmetriebrechung implementiert, welche aufeinanderfolgende Bewegungen desselben Fahrzeugs verbietet:
forall(v in 1..r, s in 1..steps-2) (move[v,s] * move[v,s+1] = 0)
¶ Modellierung mit Answer Set Programming (ASP)[2:6]
Cian et al. präsentieren in ihrer Arbeit zwei ASP-Modellierungen. Während der erste Ansatz dem der Constraint-Programmierung ähnelt, erwies sich der zweite, hier vorgestellte Ansatz als deutlich performanter. Wie vorher erwähnt, wurde dieser für die Solver clingo und DLV entwickelt. Im Gegensatz zur CP Modellierung, welche Variablenbereiche einschränkt, definiert ASP das Problem durch Fakten, welche die Instanz repräsentieren, und Regeln, welche die Logik implementieren. ASP benutzt einen sehr ähnliche Syntax zu Prolog, erweitert diesen aber um spezifische Konstrukte (wie Choice Rules und Kardinalitätsbeschränkungen).
Die Modellierung beginnt hier mit den Fakten der Instanz. grid(1..6, 1..6). definiert das Spielfeld und time(0..t). setzt die Anzahl Zeitschritte fest. Weitere Fakten sind exit(5, 4)., move_amount(1..6) und direction(up; down; left; right)..
Farzeuge werden durch das Prädikat vehicle(Index, Size, Direction). definiert, wobei Direction entweder horiz oder vert ist. Die initial Position wird durch das Prädikat position(A, T, X, Y). definiert, wobei in den ersten Zeitschritt T = 0 ist. X und Y sind die initial Koordinaten, wobei, sowie be CP, einer der Werte fixiert ist, und der andere der kleinste belegte Wert ist und A ist der Index des Fahrzeugs.
¶ Zustandsrepräsentation und Regeln
Anstatt paarweise Kollisionsprüfungen durchzuführen, leitet das ASP-Modell ab, welche Zellen zu einem Zeitpunkt belegt (busy) sind. Dies geschieht durch Regeln, die die Größe und Ausrichtung der Fahrzeuge berücksichtigen. Eine Zelle gilt als free(X, Y, T), wenn sie nicht busy ist. Dies vereinfacht die Kollisionsabfrage drastisch, da lediglich geprüft werden muss, ob benötigte Zellen "frei" sind. Wir definieren auch, ob ein gegebenes Fahrzeug movable ist.
# Vertikale Fahrzeuge (ähnliche Regel für horizontale nicht angegeben)
busy(X, Y..Y+S-1, T) :- grid(X, Y), time(T), vehicle(A, S, vert), position(A, T, X, Y).
# Movable für Richtung `up` (andere Richtungen nicht angegeben)
movable(A, T, up, N) :-
vehicle(A, S, vert), position(A, T, X, Y),
grid(X, Y-N), -----------------------------------------------> Ziel muss auf dem Gitter sein
N { free(X, Y-N..Y-1, T) } N, --------------------------------> Exakt N Zellen müssen frei sein
move_amount(N).
Die Auswahl des Spielzugs erfolgt durch eine Choice Rule mit Kardinalitätsbeschränkung. Diese erzwingt, dass zu jedem Zeitpunkt (außer dem letzten) genau eine Bewegung ausgeführt wird: 1 { move(A, T, D, N) : vehicle(A, S, D), direction(D), movable(A, T, D, N), move_amount(N) } 1 :- time(T). Diese Regel besagt, dass exakt einen Zug aus der Menge aller möglichen Züge (movable) ausgewählt werden soll und das Prädikat move(...) gesetzt werden soll.
Nun muss noch die Position zum Zeitpunkt basiert auf der gewählten Aktion evaluiert werden. Hierfür wird in ein Fahrzeug, welches sich bewegt hat, und Fahrzeuge, welche sich nicht bewegen, unterteilt.
# Bewegung nach links (andere Richtungen nicht aufgeführt)
position(A, T+1, X-N, Y) :-
move_amount(N), time(T), time(T+1),
move(A, T, left, N), movable(A, T, left, N),
vehicle(A, S, horiz), position(A, T, X, Y), grid(X, Y).
# Fahrzeug unbewegt
position(A, T+1, X, Y) :-
grid(X, Y), time(T), time(T+1),
not moved(A, T), position(A, T, X, Y),
vehicle(A, S, O).
Schlussendlich wird das Ziel als Bedingung formuliert. Es wird gefordert, dass das rote Auto (Index 1) zum Zeitpunkt auf den Koordinaten des Ausgangs steht:
goal :- position(1, t, X, Y), exit(X, Y).
:- not goal. ---> mit der kopflosen Regel wird hier gefordert, dass dieser Zustand nicht erlaubt ist
Der Solver sucht nun nach einem Answer Set, das diese Bedingung erfüllt und somit eine gültige Lösungssequenz repräsentiert .
Anmerkung: Der Artikel hatte in der Definition von position sehr warscheinlich ein Tippfehler, welchen ich hier korrigiert habe. Vom Syntax und der Logik hat das extra Prädikat vTime(T) keinen Sinn gemacht.
¶ Experimentelle Ergebnisse [2:7]
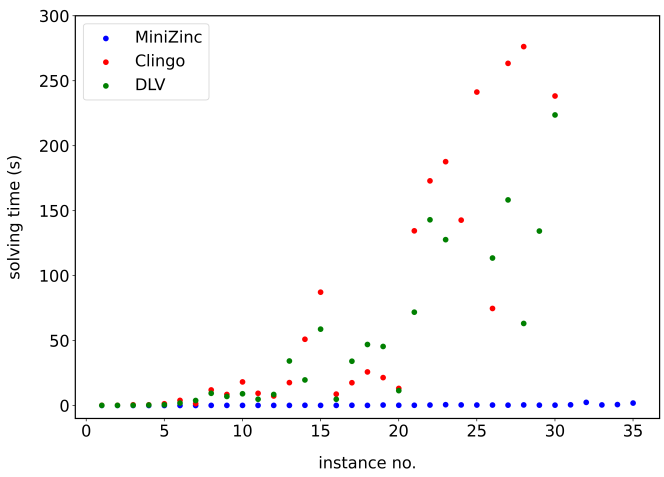
Um die Effizienz der beiden deklarativen Modellierungen zu vergleichen, führten Cian et al. Laufzeitmessungen auf einem System mit einer AMD Ryzen 7 4700U CPU und 16 GB RAM durch. Als Solver kamen dabei folgende Versionen zum Einsatz:
- CP: Der Lazy Clause Generation Solver Chuffed (v0.10.4) für das MiniZinc-Modell. Andere Solver wie Gecode oder OR-Tools zeigten in Vorabtests eine schlechtere Performance.
- ASP: Die Solver Clingo (v5.4.0) und DLV (v2.1.1).
¶ Datensätze
Die Evaluation erfolgte auf zwei unterschiedlichen Datensätzen, um sowohl einfache als auch komplexe Szenarien abzudecken. Der erste Datensatz ist ein Satz von 100 Instanzen, basierend auf dem physischen Spiel und ähnlichen Konfigurationen, mit optimalen Lösungssequenzlängen zwischen 5 und 17 Schritten. Der zweite ist ein Satz von 35 komplexen Instanzen aus der Datenbank von Michael Fogleman[4], mit Lösungssequenzlängen zwischen 6 und 51 Schritten.
¶ Resultate
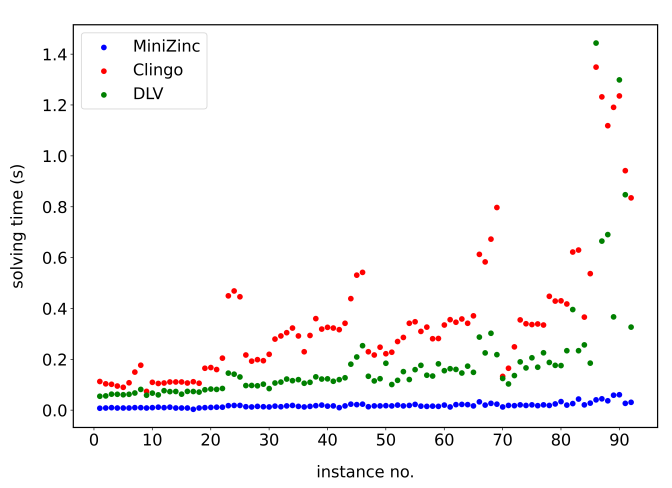
Die Ergebnisse zeigen einen klaren Unterschied in der Leistungsfähigkeit der Ansätze abhängig von der Komplexität der Lösung. Bei kürzeren Lösungssequenzen unter 30 Schritten zeigten sich beide Ansätze als äußerst effizient. Bei dem ersten Datensatz wurden die meisten Lösungssequenzen in unter 0.2 Sekunden gefunden. Auch im zweiten Datensatz blieb ASP bis zu einer Lösungssequenzlänge von etwa 30 Schritten sehr schnell. Wichtigerweise ist CP in den einfachen Konfigurationen dennoch schneller als ASP.
Wenn man sich aber Konfigurationen mit längeren Lösungssequenzen anschaut, wird die Differenz in den Ansätzen schnell klar. Während die Laufzeit der ASP-Solver bei Lösungssequenzen über 30 Schritten drastisch anstieg, änderte sich die Laufzeit von dem CP-Modell kaum im Vergleich. Für die schwierigste Instanz mit 51 Schritten benötigten die ASP-Solver bis zu 20 Minuten (bei einem gesetzten Timeout von 5 Minuten für die regulären Tests). Im Vergleich dazu war der Chuffed-Solver in der Lage, selbst diese schwierigen Instanzen in weniger als einer Sekunde zu lösen.
Innerhalb der ASP-Solver zeigte DLV bei den komplexesten Instanzen eine leichte Performance-Überlegenheit gegenüber Clingo, während beide Solver bei Standardeinstellungen vergleichbare Ergebnisse für einfachere Probleme lieferten.
¶ Diskussion der Ergebnisse
Die Autoren geben im Paper einen Erklärungsansatz für die massive Diskrepanz bei langen Lösungssequenzen. Der Unterschied liegt scheinbar eher an der Art der Lösungsfindung und nicht, wie bei ähnlichen Problemen mit langen Sequenzen in ASP oft üblich, an der Größe der Instanziierung (Grounding). Die Autoren stellten fest, dass selbst bei den schwierigsten Instanzen die generierte Datei eine handhabbare Größe von etwa 6 MB (ca. 71.000 Zeilen) aufwies, wodurch kein extremes Hinderniss entstand. Vielmehr scheint die Suchstrategie des CP-Solvers Chuffed, der Lazy Clause Generation verwendet, deutlich besser für die Suche in diesem spezifischen Zustandsraum geeignet zu sein als die Standard-Heuristiken der verwendeten ASP-Solver, die ohne Optimierungen eingesetzt wurden. Eventuell hätten die Autoren die Leistung der ASP Solver durch anwendungsspezifische Heuristiken[5] verbessern können, dies wurde aber für zukünftige Arbeiten gelassen.
¶ Bildquellen
- Abb. 1: https://m.media-amazon.com/images/I/71ztQTH+sGL.jpg
- Abb. 2, 3: Figure 3 aus [2][2:8]
- Abb. 4: Figure 4 aus [2][2:9]
- Abb. 5: Figure 6 aus [2][2:10]
- Abb. 6: Figure 7 aus [2][2:11]
¶ Referenzen
Wikipedia contributors. (n.d.). Rush Hour. In Wikipedia. Retrieved January 13, 2025, from https://en.wikipedia.org/wiki/Rush_Hour_(puzzle) ↩︎ ↩︎
Cian, L., T. Dreossi, and A. Dovier. (2022). Modeling and Solving the Rush Hour Puzzle. CEUR-WS. https://air.uniud.it/handle/11390/1234670 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Flake, G. W., & Baum, E. B. (2002). Rush hour is PSPACE-complete, or "Why you should generously tip parking lot attendants". Theoretical Computer Science, 270(1-2), 895-911. ↩︎
Michael Fogleman. (2018). Solving Rush Hour, the Puzzle. Retrieved January 14, 2025, from https://www.michaelfogleman.com/rush/#DatabaseDownload ↩︎
M. Gebser, B. Kaufmann, J. Romero, R. Otero, T. Schaub, P. Wanko. (2013). Domain-specific
heuristics in answer set programming. Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, July 14-18, 2013, Bellevue, Washington, USA, AAAI Press, 2013. http://www.aaai.org/ocs/index.php/AAAI/AAAI13/paper/view/6278. ↩︎