¶ Nested Rollout Policy Adaptation[1]
Nested Rollout Policy Adaptation (NRPA) ist ein auf Monte Carlo Tree Search (MCTS) und Nested Monte Carlo Search (NMCS) aufbauender Algorithmus. Wie NMCS verwendet er Rekursion und merkt sich die bisher beste gefundene Sequenz pro Level, das heißt die Sequenz, die zu der insgesamt höchsten Punktzahl geführt hat. Allerdings sind Rollouts hier nicht mehr zufällig wie in MCTS und NMCS, sondern werden von einer dynamisch angepassten Policy geleitet, die die Wahrscheinlichkeit eines Zugs bestimmt.
¶ Pseudocode
Der Pseudocode des Algorithmus' besteht aus zwei Teilen: der NRPA() Funktion und der Adapt() Funktion:
NRPA(level, pol):
if level==0: //base rollout policy
node = root(), ply = 0, seq = {}
while num_child(node)>0:
choose seq[ply] = child with probability proportional to exp(pol[code(node,i)])
node = child(node, seq[ply])
ply += 1
return (score(node), seq)
else:
best_score = -infinity
for N iterations:
(result, new) = NRPA(level-1, pol)
if result >= best_score:
best_score = result
seq = new
pol = Adapt(pol, seq)
return (best_score, seq)
ply: Rekursionstiefe
seq: (beste) gefundene Sequenz
best_score: beste gefundene Punktzahl
node: Spielzustand
N: Anzahl Iterationen (globaler Parameter, z.B. 100)
pol: Policy
Adapt(pol, seq):
node = root(), pol' = pol
for ply = 0 to length(seq)-1
pol'[code(node, seq[ply])] += Alpha
z = sum exp(pol[code(node, i)])
for children i of node:
pol'[code(node, i)] -= Alpha*exp(pol[code(node,i)])/z
node = child(node, seq[ply])
return pol'
ply: Rekursionstiefe
seq: beste gefundene Sequenz
node: Spielzustand
Alpha: globaler statischer Parameter (z.B. 1)
pol: Policy
code(node, child): Kennung des Zugs, der von Zustand node zu Kindzustand child führt
Gestartet wird eine Suche mit NRPA(level, pol), wobei pol die Startpolicy ist. Liegen noch keine weiteren Informationen vor, wird die Policy in der Regel als Nullvektor initialisiert. Einstellbare Werte sind level (wobei es hier nur wenige sinnvolle Werte gibt), sowie die globalen statischen Variablen Alpha und N.
¶ Funktionsweise
Wie bei NMCS geht NRPA nach seinem Aufruf zuerst in tiefere Rekursionslevel, bis Level 0 erreicht wird (allerdings ohne sich den aktuellen Knoten zu merken). Sobald die Rekursion bei diesem Anker angekommen ist, werden nacheinander N Rollouts von der Wurzel aus gestartet. Anstatt zufällig den jeweils nächsten Zug zu wählen, hängt die Wahrscheinlichkeit von der Policy Tabelle ab, die für jeden Zug ein Gewicht enthält. Sie ist nicht zwingend allgemeingültig und muss nicht für jeden beliebigen Startknoten ein gutes Ergebnis liefern, sondern gilt in der Regel nur für den aktuellen Aufruf. Mit welcher Wahrscheinlichkeit ein Zug gewählt wird, lässt sich anhand der folgenden Formel berechnen:
: Wahrscheinlichkeit eines Zugs
: Zug
: Gewicht eines Zugs
: Menge aller Züge
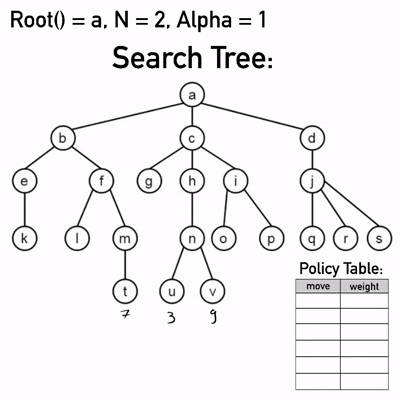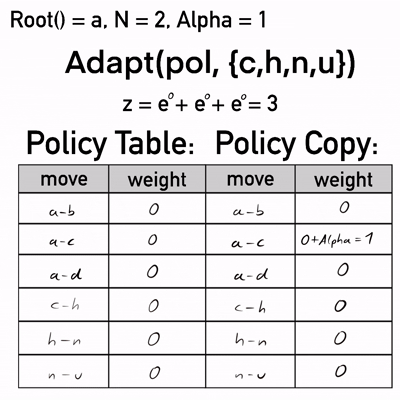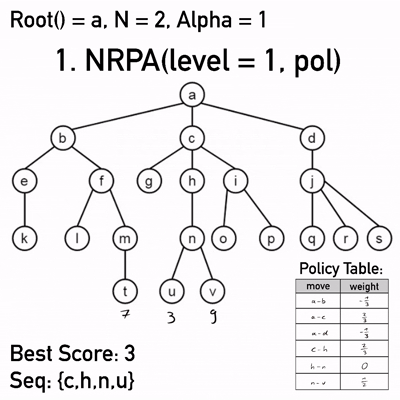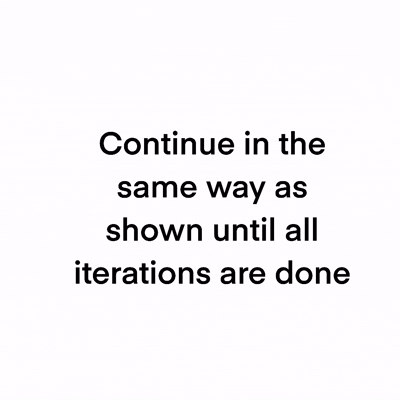
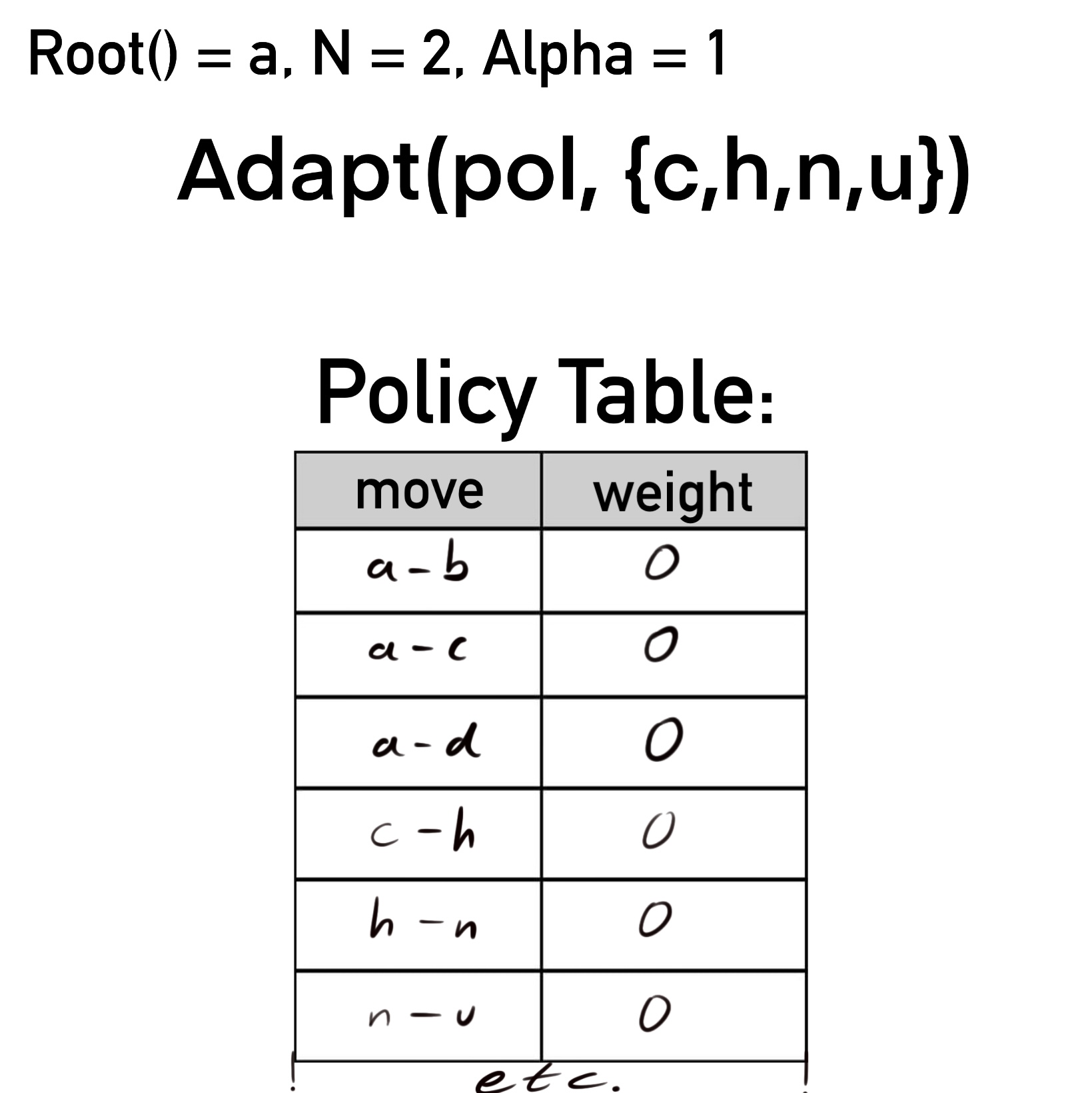
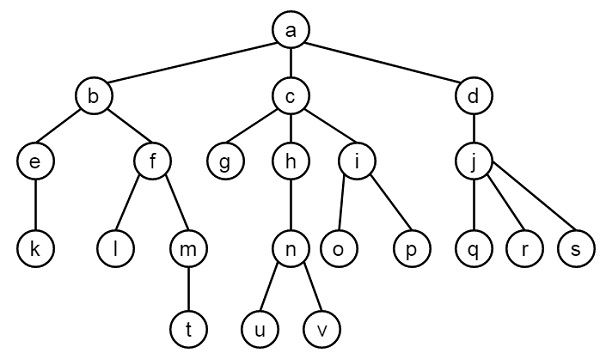
Die Ausführung einer NRPA Suche wird in der nebenstehenden Abb. 1 graphisch gezeigt und im folgenden Text erläutert:
Die Wurzel, und damit der aktuelle Spielzustand, ist der Knoten a. Für N wurde der Wert 2 der Einfachheit halber gewählt, damit das Beispiel nicht seinen Rahmen sprengt. In der wirklichen Implementierung sollte N deutlich größer sein, sodass NRPA sich der besten Sequenz annähern kann und keine ungünstigen Zwischenergebnisse entstehen. Idealerweise gibt es also nach dem Finden einer neuen besten Sequenz genug weitere Durchläufe von Adapt(), dass diese Sequenz tatsächlich auch der wahrscheinlichste Pfad wird. Alpha ist 1, was auch in der Praxis realistisch ist.
Von a aus wird nun die Funktion das erste Mal aufgerufen mit NRPA(level = 2, pol). Die Gewichte in der Policy Tabelle sind aufgrund fehlender Informationen vorerst mit ausschließlich Nullen initialisiert. Hier wird nun das erste Mal eine Rekursion ausgeführt und NPRA(level = 1, pol) aufgerufen, was widerum NPRA(level = 0, pol) ausführt. In jedem Level wird jeweils die beste Sequenz seq auf eine leere Liste und der best_score auf minus Unendlich gesetzt.
Wie bei NMCS handelt es sich bei Level 0 um das Rollout. Da die Policy Tabelle bisher nur gleiche Gewichte enthält, ist dieses zufällig, obwohl es auf der Tabelle basiert. Ist ein Knoten ohne Kind (Blattknoten) erreicht, wird die Endpunktzahl, hier 3, und die Sequenz, hier {c,h,n,u}, zu Level 1 zurückgegeben.
Dort ist für best_score noch der Anfangswert von minus Unendlich gespeichert, was kleiner ist als der zurückgegebene Wert. Es werden also best_score und seq aktualisiert. Hier ist zu beachten, dass anders als bei NMCS der neue Wert größer gleich dem gespeicherten geprüft wird. Dies ergab in den Tests des Autors des referenzierten Papers deutlich bessere Resultate, vermutlich, weil es die Exploration des Suchbaums fördert.
Als letzter Schritt in der Schleife wird die namensgebende Adapt() Funktion mit der Policy Tabelle von Level 1 und der gespeicherten Sequenz aufgerufen. Erstere enthält alle Züge, von welchen hier für die Übersichtlichkeit nur die relevantesten aufgeführt sind.
Im ersten Schritt wird die Policy nach pol' kopiert.
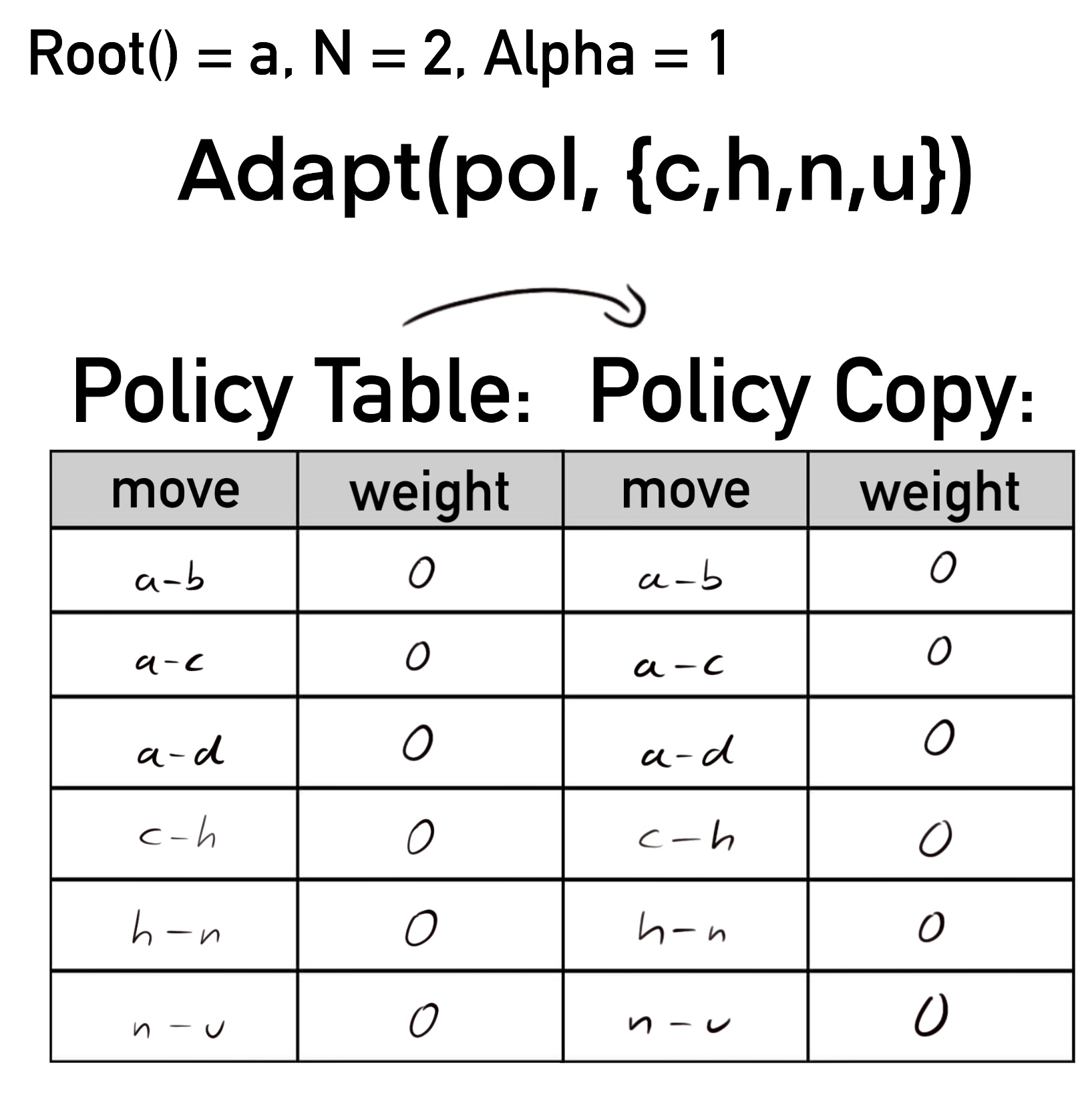
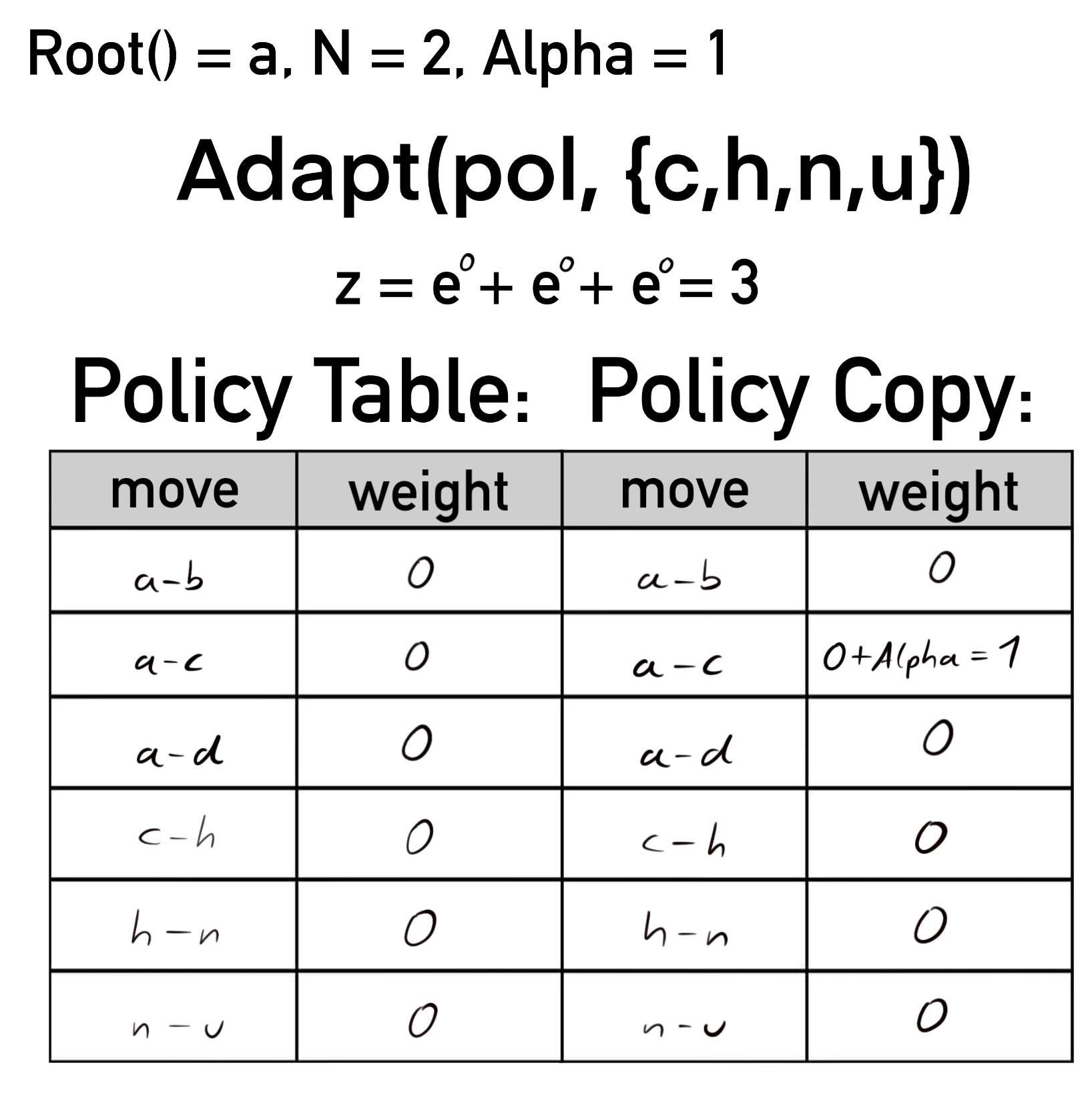
Dann wird node auf a (also die Wurzel) gesetzt. Allgemein erhöht sich in der Policykopie pol' das Gewicht desjenigen Zugs um Alpha, welcher von node zu dem jeweils aktuellen Element der Sequenz führt. Kurz: Alle in der Sequenz vorkommenden Züge werden um Alpha schwerer. Hier wächst also das Gewicht des Zugs a-c, welcher von node zu seq[0] führt.
pol'[code(node, seq[ply])] += Alpha
Basierend auf der alten Policy Tabelle (links), kann außerdem die Summe (z) aller Exponenten der Gewichte der Züge gebildet werden, die zu Kindern i von node führen, was hier drei ergibt.
z = sum exp(pol[code(node, i)])
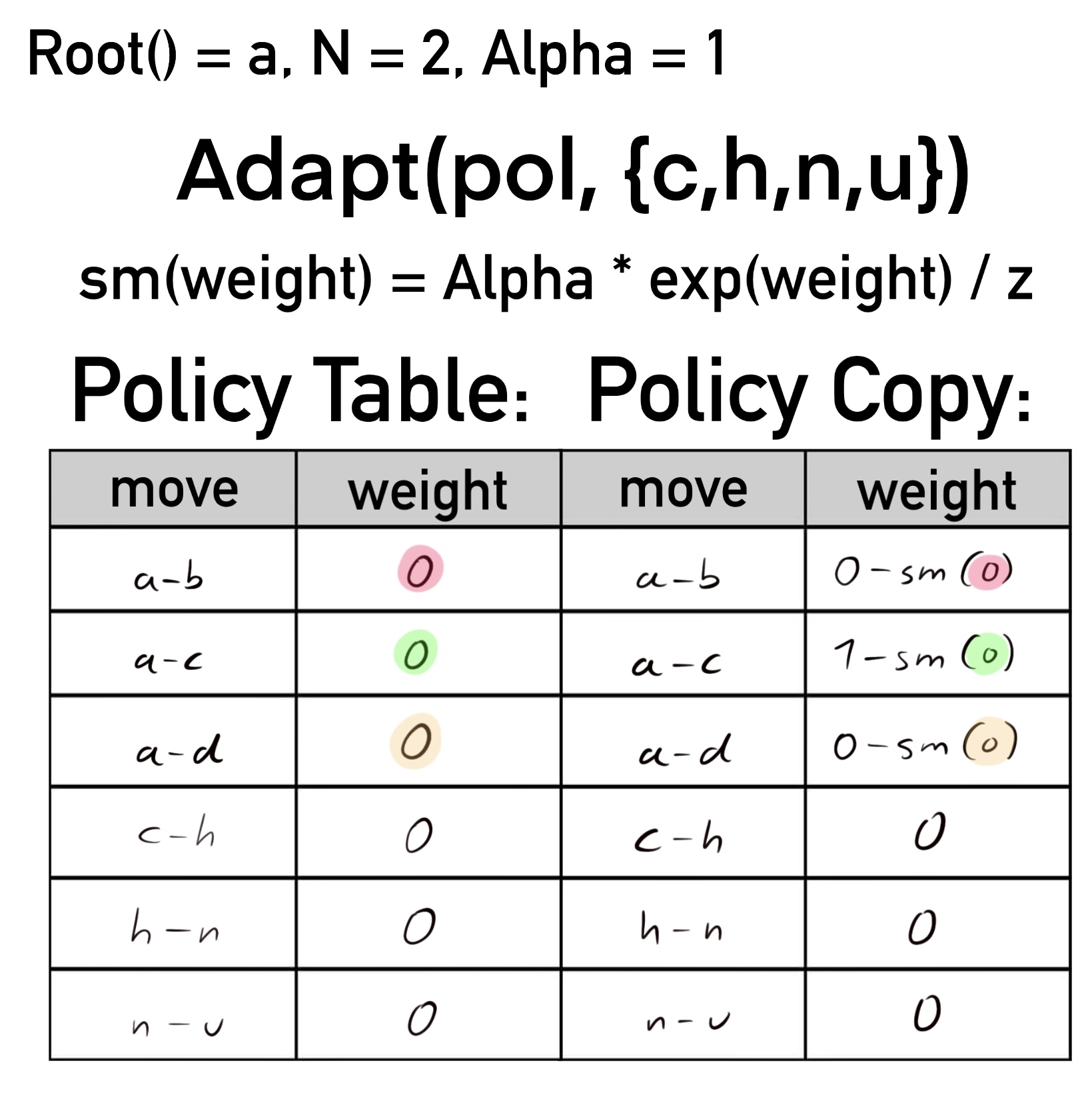
Nach der Formel für das Berechnen der Zugwahrscheinlichkeiten würde diese Gewichtsverteilung für die Züge a-b, a-c und a-d eine Gesamtwahrscheinlichkeit von rund 111% bilden. Das ist kein valider Wert. Um wieder eine Gesamtwahrscheinlichkeit von 100% zu erreichen, wird für alle Kinder i von node die Softmax-Funktion () auf die alten Gewichte in pol angewendet und das Ergebnis jeweils von dem Gewicht des Zugs in der neuen Policy Tabelle pol' abgezogen.
pol'[code(node, i)] -= Alpha*exp(pol[code(node,i)])/z
Hiernach beginnt die Schleife erneut, diesmal mit node auf das erste Element in der Sequenz gesetzt, in diesem Fall c. Wieder wird das Gewicht von dem Zug, der von c zu seinem in der besten Sequenz enthaltenen Kind (h) führt um Alpha erhöht. c hat wie sein Elternknoten drei Kinder, was eine Summe z von drei ergibt. Von den Gewichten aller Kinder cs wird nun auch das Ergebnis der Softmax-Funktion abgezogen. Züge c-g und c-i sind der Übersichtlichkeit halber nicht in der Tabelle enthalten, betragen aber nach diesem Schritt ebenfalls .
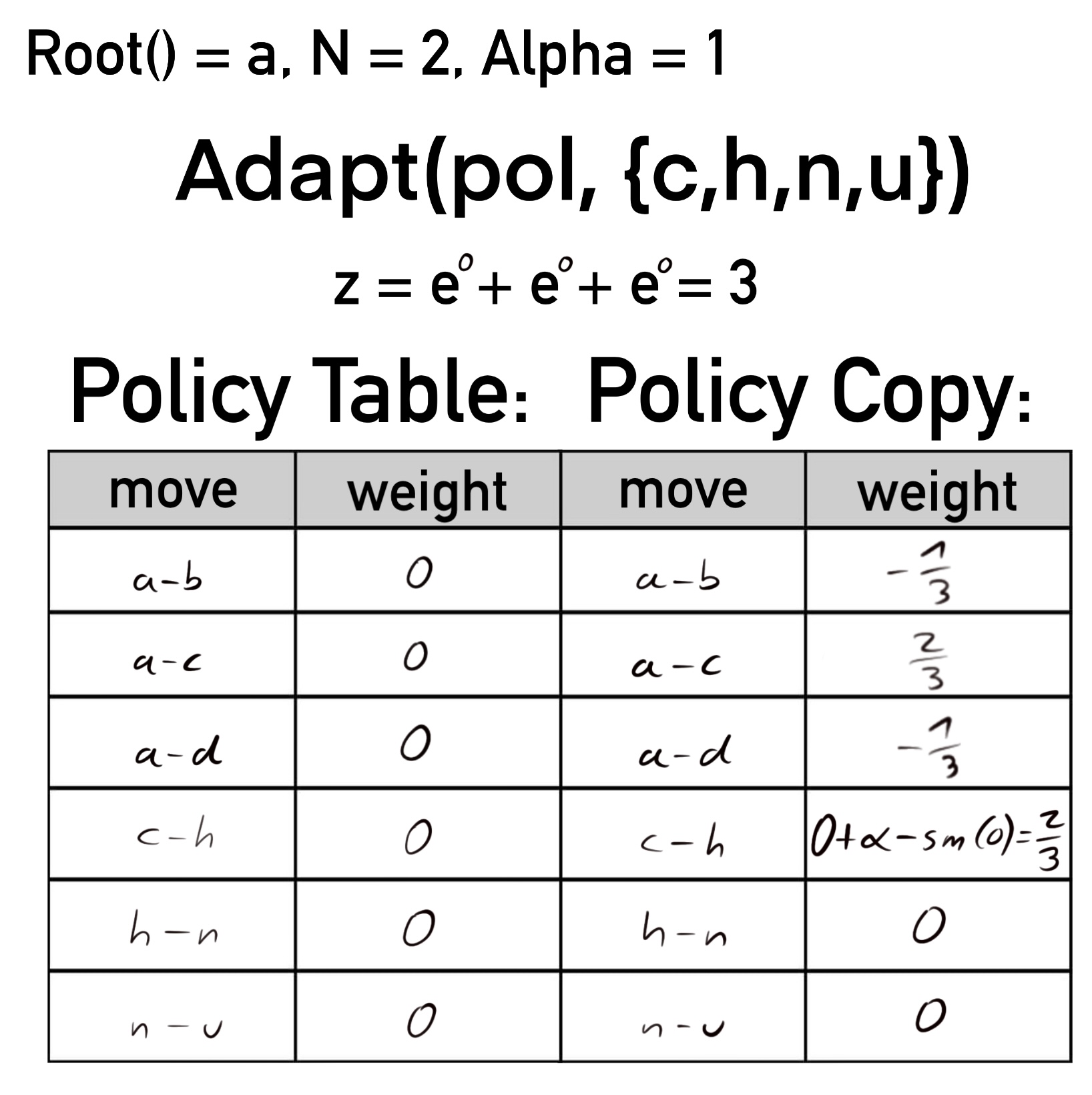
Knoten h hat nur ein Kind. Die Wahrscheinlichkeit, von hier den Kindknoten n zu wählen, wird unabhängig von dem Gewicht des entsprechenden Zugs immer 100% sein. Der NRPA Algorithmus jedoch hält dieses Gewicht konstant bei Null.
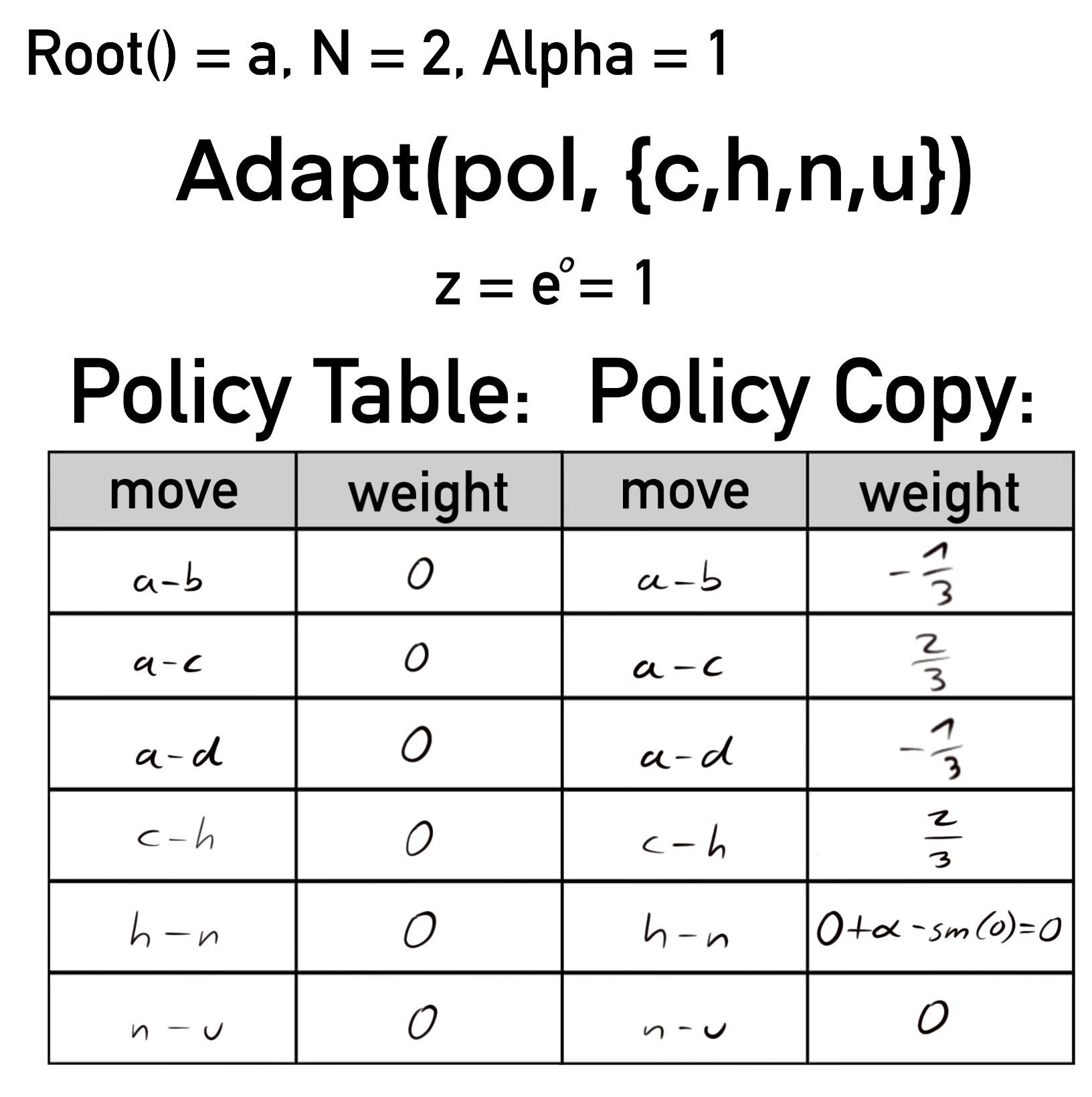
In der letzten Iteration von Adapt() ist node gleich n. Dieser Knoten hat zwei Kinder, damit eine Summe z von zwei und entsprechend wird nach dem Aufaddieren von Alpha auf den Zug n-u von demselben und Zug n-v abgezogen.
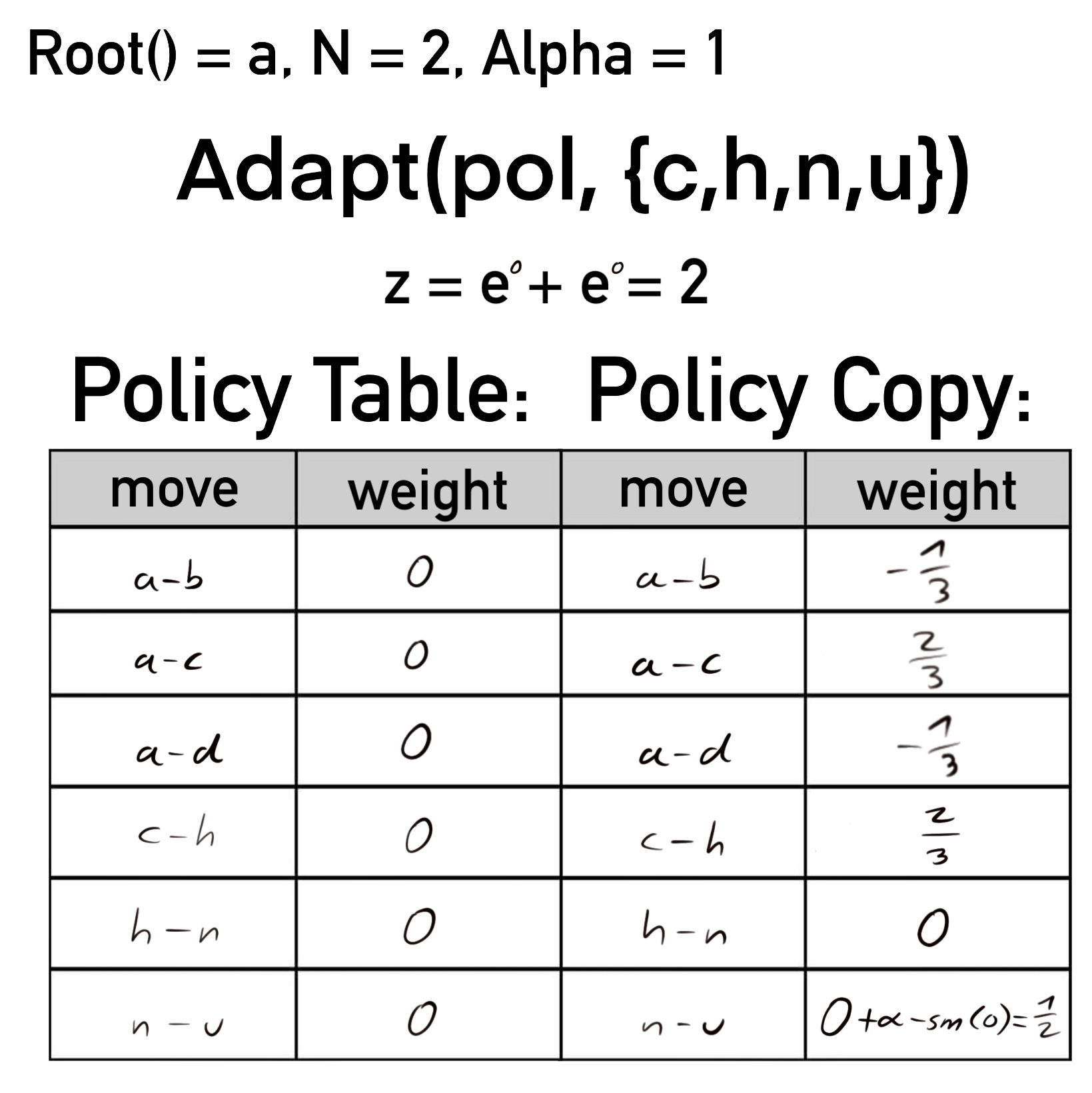
Damit ist das Ende der Sequenz erreicht und die Schleife bricht ab. An Level 1 von NRPA wird schließlich pol' zurückgegeben. In der folgenden Abbildung findet sich der relevante Ausschnitt:
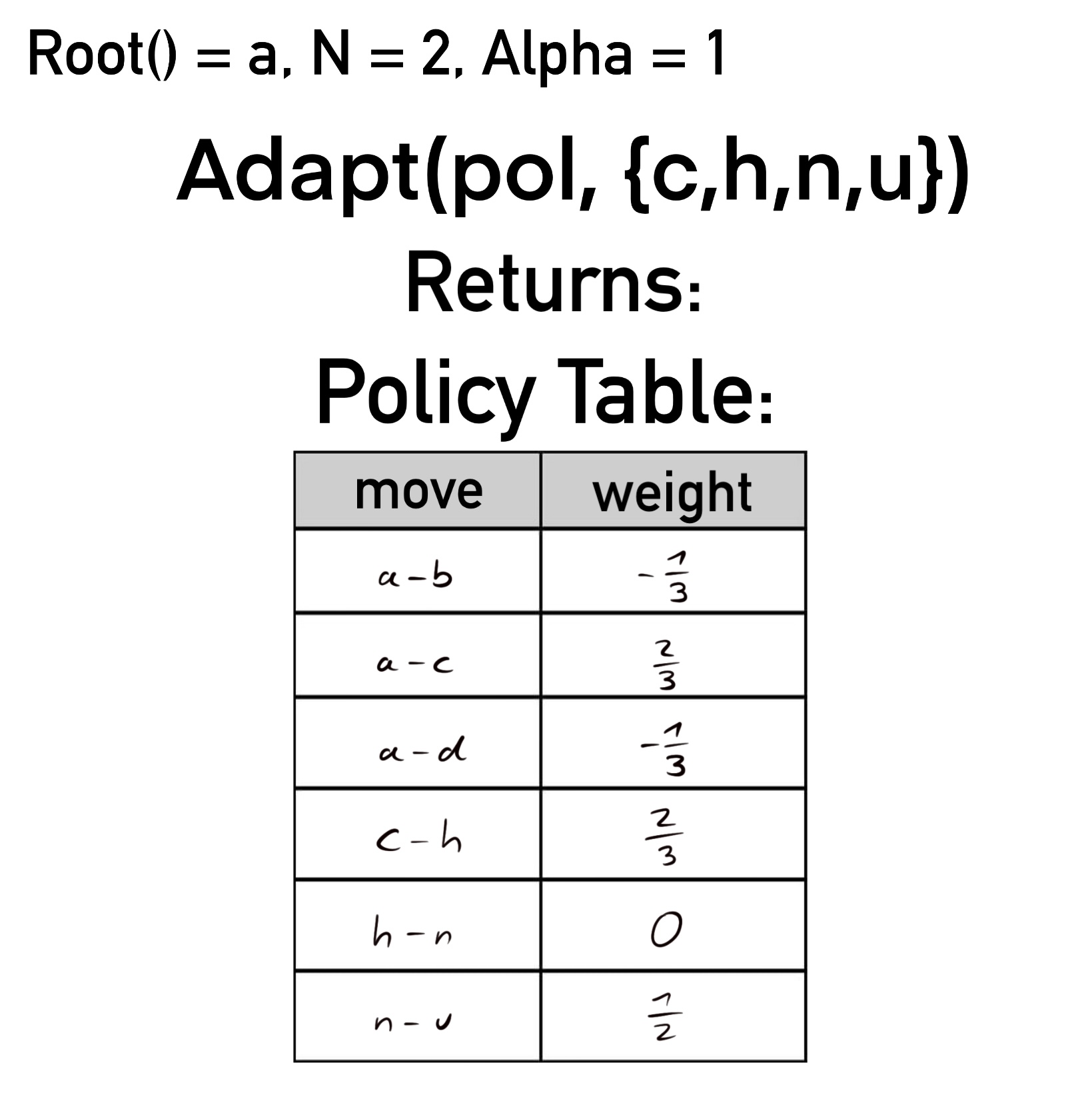
Der Zug a-c wird nun mit diesem Gewicht beispielsweise mit einer Wahrscheinlichkeit von rund 57,62% gewählt, a-b und a-d mit jeweils 21,19%. Mit dieser errechneten Wahrscheinlichkeitsverteilung startet NRPA das nächste Level 0 Rollout.
Im Beispiel liefert dieses nächste Rollout eine Endpunktzahl von 1 zurück. Die gespeicherten Werte für Punktzahl und Sequenz bleiben demnach erhalten und letztere wird erneut in die Adapt() Funktion gegeben. Dadurch wird der Bias, Züge aus dieser Sequenz zu wählen, weiter verstärkt. Es macht keinen Unterschied, ob der letzte Aufruf der Rekursion eine bessere Punktzahl geliefert hat: Die Adapt() Funktion wird unabhängig davon immer aufgerufen.
Level 1 hat nun N Iterationen des niedrigeren Levels abgeschlossen, das bedeutet, es gibt die beste Punktzahl (3) und die entsprechende Sequenz ({c,h,n,u}) zurück. In Level 2 beträgt best_score noch minus Unendlich, also werden best_score und die Sequenz mit den neu erhaltenen Werten ausgetauscht. Die Policy, hier noch die anfängliche Nullpolicy, da Policies nur von „oben nach unten“ weitergegeben werden, wird auf Basis der besten Sequenz adaptiert. Dann startet Level 2 den nächsten Level 1 NRPA-Aufruf, mit Übergabe seiner angepassten Policy.
Der Vorgang wiederholt sich bis alle Iterationen abgeschlossen sind. Am Ende wird die beste, über die ganze Suche gefundene Punktzahl und die entsprechende Sequenz zurückgegeben, von welcher dann der erste Zug ausgeführt werden kann. Das referenzierte Paper beschreibt nicht weiter, ob die Policy Tabelle über das gesamte Spiel oder nur die Suche nach einem einzigen Zug erhalten wird, oder zum Beispiel außerhalb der NRPA Funktion eine zusätzliche Policy Tabelle existiert, die jeweils mit der von NRPA zurückgegebenen seq angepasst und in den neuen NRPA Aufruf als Startpolicy gegeben wird. Es scheint aber sinnvoll, nicht mit jeder Suche bei Null (beziehungsweise mit einer Nullpolicy) beginnen zu müssen.
¶ Zugcodes
Bei der Umsetzung des NRPA Algorithmus' sollte darauf geachtet werden, dass Codes für Züge zu Kinddknoten (code(node,i)) eindeutig sind, damit ihnen arbiträre Gewichte und entsprechend unterschiedliche Wahrscheinlichkeiten zugewiesen werden können.
Des weiteren sollten Codes für Züge sich nicht tiefer in der Sequenz wiederholen, damit beim Zuweisen einer höheren Wahrscheinlichkeit zu einem von ihnen die folgende Auswahl unbeeinflusst bleibt. Das würde den Lerneffekt von NRPA negativ beeinflussen.
Weil verschiedene Codes einzeln in der Tabelle verzeichnet sind und entsprechend einzeln gesucht werden, kann es trotzdem sinnvoll sein, ihre Anzahl zu minimieren und Codes mehr als einmal zu vergeben. Dabei sollten aber Züge, die den gleichen Code teilen, mindestens einen ähnlichen Wert haben.
¶ Überblick
Insgesamt versucht NRPA, eine geschickte Balance zwischen Exploration (Finden neuer Pfade) und
Exploitation (Ausnutzen bekannter, guter Lösungen) zu finden. Dadurch, dass die Suche die Züge nicht direkt am Baum ausführt, sondern lediglich die Policy anpasst, bleibt sie flexibler. Selbst schlechter gewertete Züge haben noch eine Wahrscheinlichkeit gewählt zu werden und neue, eventuell bessere Ergebnisse aufzudecken. Gleichzeitig geht durch das Speichern der besten Sequenz keine gute Punktzahl verloren.
Obwohl der Algorithmus auf Monte Carlo Tree Search basiert, muss nicht zwingend eine Baumstruktur verwendet werden. Für manche Spiele, bei denen es möglich ist, über verschiedene Zugsequenzen zu dem selben Spielstand zu kommen, kommt auch ein DAG als Datenstruktur in Frage.
Auch wenn NRPA sowohl in Laufzeit, als auch in Qualität der Lösungen seinem Vorbild NMCS bereits überlegen ist (zumindest in den vom Autor des referenzierten Papers aufgestellten Tests in 2011), kann es noch weiter optimiert werden. Beispielsweise mit Parallelisierung oder dem Anwenden von domänenspezifischem Wissen.
¶ Bildquellen
Abb 1.: Animation und Beispiel selbst erstellt, Abbildung des Suchbaums von https://www.tutorialspoint.com/prolog/images/tree_data_structure.jpg
Rest: Einzelne Frames der selbsterstellten Animation
{kind=link}