¶ Allgemeines
Konane, auch bekannt als hawaiianisches Dame[1], ist ein 2-Spieler-Brettspiel, bei dem Spieler abwechselnd die Steine des Gegners durch Springen schlagen. Das Spiel endet, wenn ein Spieler keinen Zug mehr ausführen kann - dieser Spieler verliert.
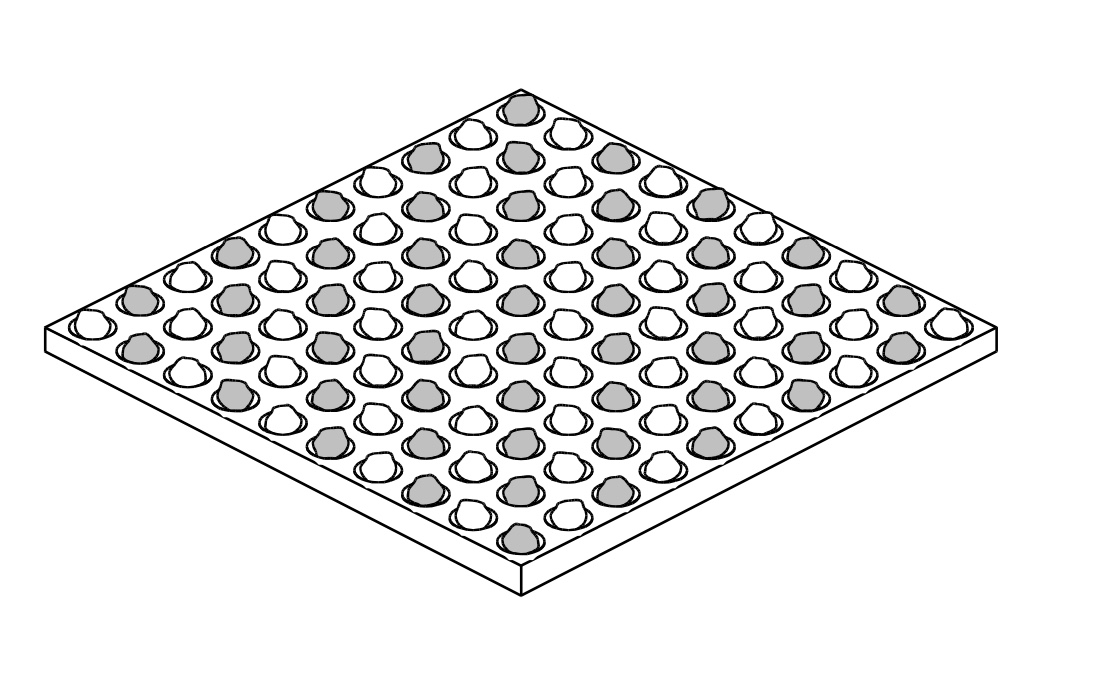
Abbildung 1: Konane Spielbrett [2]
¶ Spielregeln
¶ Ziel
Ziel des Spiels ist es, mit den eigenen Spielfiguren den letzten möglichen Spielzug durchzuführen
¶ Aufbau
Das Spiel wird auf einem quadratischen n x n-Brett (meistens 8 x 8) mit abwechselnd schwarzen und weißen Kästchen (Schachbrettmuster) gespielt. Zu Beginn des spiels wird jedes weiße Feld mit einer weißen Spielfigur belegt und jedes schwarze Feld mit einer schwarzen Spielfigur. Dann nimmt der Spieler mit den schwarzen Figuren eine seiner Figuren vom Feld. Diese Figur muss entweder in einer der Ecken desSpielbretts stehen oder genau in der Mitte der mittleren Diagonalen (siehe Abbildung 2). Anschließend nimmt der weiße Spieler eine seiner Figuren, die an das nun freie Feld angrenzt, vom Spielfeld und das Spiel geht los.

Abbildung 2: Spielbrett in Startaufstellung [3]
¶ Spielverlauf und Regeln
Die Spieler bewegen awechselnd eine Spielfigur über das Spielfeld. Dabei gelten folgende Regeln für einen Zug:
- Eine Spielfigur darf nur in einer horizontalen oder vertikalen Linie ziehen
- Eine Spielfigur muss auf einem freien Feld auf dem Spielbrett ankommen
- Eine Spielfigur bewegt sich, indem sie eine gegnerische Spielfigur überspringt. Die übersprungene Spielfigur wird aus dem Spiel genommen ("geschlagen")
- Eine Spielfigur kann in enem Zug mehrere Spielfiguren überspringen, wenn diese entlang einer Linie stehen (Abbildung 3). Das mehrfache Überspringen ist optional, es kann also auch obwohl es möglich ist mehrfach zu springen, nur ein Sprung gemacht werden.
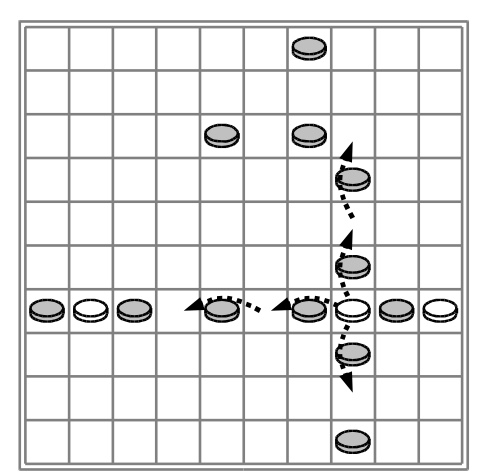
Abbildung 3: Mögliche Spielzüge für den weißen Spieler[2:1]
Das Spiel endet, wenn ein Spieler keinen gültigen Spielzug mehr spielen kann. Der Spieler der zuletzt einen Zug gespielt hat gewinnt. Wie viele gegnerische Spielfiguren ein Spieler geschlagen hat spielt keine Rolle.
¶ Algorithmische Ansätze
Konane ist ein 2-Spieler Spiel mit perfekter Information. Das Spiel hat einen durchscnittlichen branching factor von 10. Das bedeutet in einem Spielbaum hat jeder Knoten im durchschnitt 10 Kindknoten.[4]
¶ Minimax-Algorithmus (Erklärung hier)
Der Minimax-Algorithmus wird in Konane eingesetzt, um den optimalen Zug zu bestimmen, indem der Spielbaum bis zu einer festgelegten Tiefe durchsucht wird. In der Arbeit von Kaitlin Hendrick[5] wurde der Minimax-Algorithmus so implementiert:
Jeder Knoten im Baum erhält einen Utility-Wert, der die Vorteilhaftigkeit des Brettzustands für den aktuellen Spieler bewertet.
Während der Spielbaumerkundung werden die Utility-Werte von den Blattknoten aus durch den Baum zurück propagiert. Ein Knoten erhält dabei den höchsten Wert seiner Kindknoten, wenn der aktuelle Spieler (MAX) am Zug ist, oder den niedrigsten Wert, wenn der Gegner (MIN) am Zug ist. Auf diese Weise simuliert der Algorithmus die optimale Strategie für beide Spieler.
Die Simulation von Zügen erfolgt über die Funktion NEXTBOARD(), die eine Kopie des aktuellen Brettzustands erstellt und die Auswirkungen eines Zuges auf das Spielfeld simuliert. Dies ermöglicht es, jeden möglichen Zug zu bewerten, ohne den ursprünglichen Brettzustand zu verändern.
 Abbildung 4 : Utility-Funktion[5:1]
Abbildung 4 : Utility-Funktion[5:1]
Die Utility-Funktion berechnet für ein übergebenes Board und einen Player einen Wert zur Bewertung der Spielsituation. Dabei wird unterschieden zwischen den 3 Fällen: a) Spieler verliert b) Spieler gewinnt und c) das Spiel ist noch nicht zu Ende.
Die Fälle a) und b) führen zu einem Gewinn für einen der beiden Spieler und müssen daher schwerer gewcihtet werden, als Spielzüge, die das Spiel nicht beenden, daher wird die Spielbrettgröße quadriert. Führt ein Spielzug nicht zum Sieg weil die Suchtiefe erreicht ist, wird die Spielbrettgröße nur verdoppelt gewichtet. So wird sichergestellt, dass der Utility-Wert für einen Spielzug der zu einem schnellen Gewinn führt höher ist als der Wert für einen späteren Sieg oder einen pielbrettzustand der noch nicht entschieden ist.

Abbildung 5: Implementierung von Minimax in Python.[5:2]
¶ Alpha-Beta-Pruning (Erklärung hier)
Aufgrund des hohen branching Faktors und der großen Anzahl an möglichen Zügen in Konane steigt die Berechnungszeit bei größeren Tiefen exponentiell an (dazu später mehr). Um Spielzüge effizienter zu berechnen wird deshalb der Minimax-Algorithmus mit Alpha-Beta-Pruning zur Berechnung verwendet.
Alpha-Beta-Pruning ist eine zusätzliche Technik, die in Kombination mit dem Minimax-Algorithmus verwendet werden kann. Ein Algorithmus mit Alpha-Beta-Pruning wählt für die gleichen Spielzustände dieselben Züge wie der Minimax-Algorithmus und sollte daher die gleiche statistische Gewinnwahrscheinlichkeit erreichen. Allerdings nutzt Alpha-Beta-Pruning eine Methode, um Zweige im Spielbaum auszuschließen, die die endgültige Entscheidung nicht beeinflussen können. Dadurch wird die rechnerische Effizienz des Algorithmus erheblich verbessert.
 Abbildung 6: Implementierung von Alpha-Beta-Pruning in Python[5:3]
Abbildung 6: Implementierung von Alpha-Beta-Pruning in Python[5:3]
¶ Erkenntnisse zu Minimax mit und ohne Alpha-Beta-Pruning
Kaitlin Hendrick lässt in einem Experiment verschiedene Player-Agents gegeneinander Spielen. Es wird unterschieden zwischen AI-Agents und Player-Agents. Ein AI-Agent sucht seine Spielzüge mit dem Minimax-Algorithmus aus Abbildung 5 und einer mit Alpha-Beta-Pruning (Abbildung 6). Beide spielen gegen einen Random-Player, der aus einer gegeben Liste mit möglichen SPielzügen zufällig einen auswählt, einen Human Player, der einen Spielzug auswählt und einen Strategy Player, der nach folgenden Regeln seinen Spielzug aus einer Liste mit möglichen Spielzügen auswählt:
- ziehe keine Figuren, die in Ecken stehen, außer es ist die einzige Möglichkeit
- ziehe nur Figuren die bedroht sind im nächsten Zug geschlagen zu werden
- ziehe keine Figuren die nicht bedroht sind
Beide AI-Agents spielten 25 Spiele gegen den Human Player und je 100 Spiele gegen die anderen beiden Player-Agents sowie den jeweils anderen AI-Agent. Dieses Turnier führte zu folgendem Ergebnis:
| Minimax Agent | Alpha-Beta Agent | |
|---|---|---|
| Siege gegen Human-Agent: | 100% | 100% |
| Siege gegen Random-Agent: | 90% | 91% |
| Siege gegen Strategy-Agent: | 89% | 89% |
| Siege gegen anderen AI-Agent: | ~50% | ~50% |
Abbildung 7: Ergebnisse von Spielen der AI-Agents mit Minimax oder Alpha-Beta-Pruning[5:4]
Um die Effizienz zu vergleichen ließ Hendrick in einem weiteren Experiment Minimax und Minimax mit Alpha-Beta-Pruning bei den Suchtiefen 2, 4 und 6 je 25 Partien gegen den Startegy-Agent spielen. Dabei wurde zu jeder Suchtiefe die Anzahl bewerteter Knoten und die durchschnittliche Spielzugdauer in ms gemessen und gegenübergestellt
| Minimax Agent | Alpha-beta Agent | |||||
|---|---|---|---|---|---|---|
| Suchtiefe | 2 | 4 | 6 | 2 | 4 | 6 |
| Zahl bewerteter Knoten | 189 | 50.093 | 4.245.710 | 178 | 11.585 | 202.735 |
| Durchschnittliche Spielzugdauer (ms) | 7,93 | 2.683,9 | 140.721,0 | 6.45 | 430,78 | 6.344,4 |
Abbildung 8 : Ergebnisse zur Effizienz[5:5]
Es lässt sich eine deutliche Steigerung der Effizienz bei Verwendung von Alpha-Beta erkennen.
¶ Künstliche Neuronale Netze (KNN)
¶ Einführung
Künstliche Neuronale Netze (KNN) sind von der funktionsweise des menschlichen Gehirns inspirierte Modelle des maschinellen Lernens. Sie bestehen aus künstlichen Neuronen und sind in der Lage Muster in Daten zu erkennen und Vorhersagen anhand dieser Daten zu treffen. Neuronen innherhalb einer Schicht sind mit allen Neuronen der anderen Schichten verbunden.[4:1]
¶ Aufbau eines Künstlichen Neuronalen Netzes
Ein künstliches Neuronales Netz besteht aus drei Schichten:
-
Eingabeschicht (Input Layer):
- Nimmt Rohdaten (z. B. Zahlen, Bilder) als Eingangswerte auf.
-
Verborgene Schicht (Hidden Layer):
- Verarbeitet die Eingaben, indem sie sie mit Gewichten multipliziert und durch Aktivierungsfunktionen leitet.
- Jede Schicht lernt komplexe Muster in den Daten.
-
Ausgabeschicht (Output Layer):
- Liefert Ergebnisse wie Vorhersagen oder Klassifikationen.
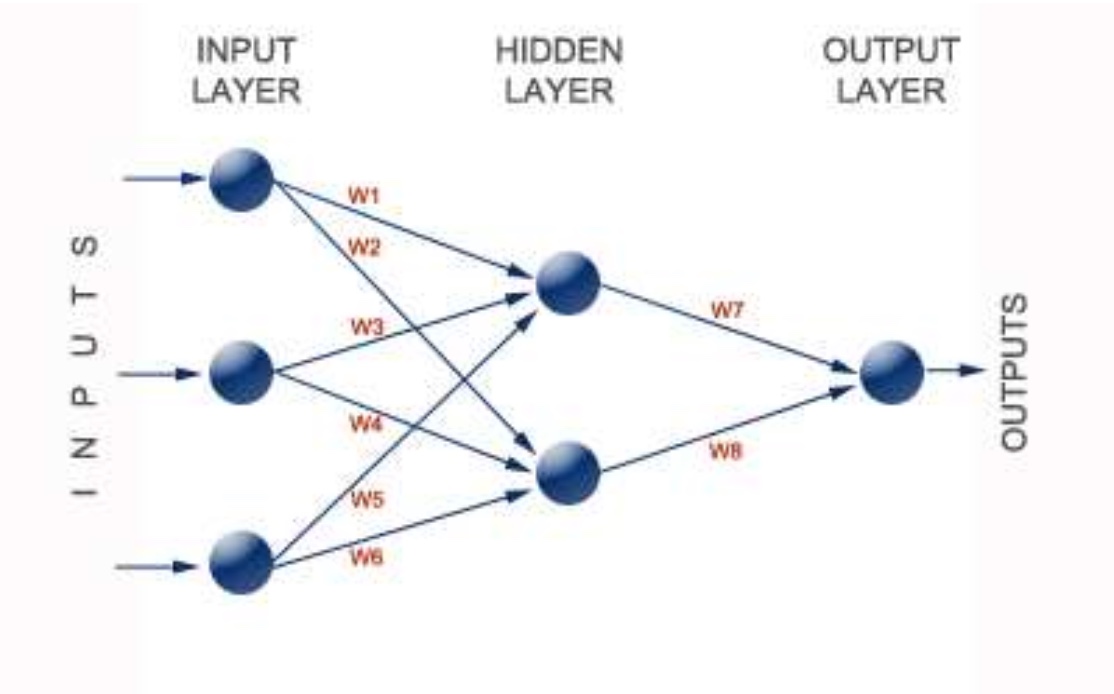 Abbildung 9: Beispiel für ein Künstliches Neuronales Netz[4:2]
Abbildung 9: Beispiel für ein Künstliches Neuronales Netz[4:2]
¶ Funktionsweise
-
Vorwärtspropagation:
- Eingabedaten werden durch die Schichten propagiert, wobei jede Verbindung ein Gewicht hat, das die Stärke des Signals bestimmt.
-
Fehlerberechnung:
- Der Unterschied zwischen der vorhergesagten und der tatsächlichen Ausgabe wird als Fehler gemessen.
-
Rückwärtspropagation (Backpropagation):
- Der Fehler wird verwendet, um die Gewichte anzupassen und das Netz zu optimieren.
Das neuronale Netz funktioniert, indem Werte den Knoten in der Eingabeschicht zugewiesen werden. Diese Werte werden durch die verborgenen Schichten propagiert, wobei sie mit den Gewichten der Verbindungen multipliziert und durch eine Aktivierungsfunktion skaliert werden. Schließlich erreicht das Signal die Ausgabeschicht, wo die Ergebnisse abgelesen werden.
¶ Stärken von Künstlichen Neuronalen Netzen
- Mustererkennung: Sie können komplexe Beziehungen in Daten erkennen, die mit traditionellen Algorithmen schwer zu erfassen sind.
- Vielseitigkeit: Sie finden Anwendung in Bereichen wie Bild- und Spracherkennung, autonomem Fahren und Spielen.
¶ Herausforderungen
- Overfitting:
- Netzwerke können sich zu stark an Trainingsdaten anpassen und auf neue Daten schlecht generalisieren.
- Rechenintensiv:
- Training erfordert spezialisierte Hardware und große Datenmengen.
Künstliche Neuronale Netze sind die Grundlage moderner künstlicher Intelligenz und bieten vielfältige Anwendungsmöglichkeiten in Wissenschaft und Industrie.
¶ Anwendung auf Konane
Im Paper von Thompson[4:3]wurden verschiedene Brettdarstellungen untersucht, die als Eingabedaten für das neuronale Netz dienen. Besonders relevant sind die Darstellungen B und C, die darauf abzielen, die Brettinformationen effizient zu kodieren.
- Daratellung A
- Jede Brettposition wird mit einem einzigen Wert kodiert:
+1für Steine des aktuellen Spielers.-1für Steine des Gegners.0für leere Felder.
Schwäche: Diese Darstellung war am wenigsten effektiv, da sie keine klare Trennung zwischen Spieler- und Gegnerpositionen bot, was das Erkennen konsistenter Muster erschwerte.
2. Darstellung B
- Jede Brettposition wird entweder mit
1(aktueller Spieler) oder0(Gegner) kodiert. Diese kompakte Darstellung verwendet weniger Eingabeknoten und reduziert somit die Netzgröße. - Vorteile:
- Gute Leistung bei geringem Rechenaufwand.
- Generalisiert gut auf neue Brettzustände.
- Schwächen:
- Die Zuordnung der Eingabeknoten variiert je nach Spielerfarbe, was das Lernen konsistenter Muster erschwert.
- Darstellung C
- Erweiterung von Darstellung B: Die Brettpositionen werden in zwei separate Eingabevektoren aufgeteilt:
- Die erste Hälfte repräsentiert die Positionen des aktuellen Spielers (
1für kontrollierte Felder,0für andere). - Die zweite Hälfte repräsentiert die Positionen des Gegners auf dieselbe Weise.
- Die erste Hälfte repräsentiert die Positionen des aktuellen Spielers (
- Vorteile:
- Feste Zuordnung der Brettpositionen erleichtert das Lernen konsistenter Muster.
- Zeigte die beste Leistung im Vergleich zu den anderen Darstellungen.
- Schwächen:
- Erfordert die doppelte Anzahl an Eingabeknoten im Vergleich zu Darstellung B, was die Netzgröße erhöht.
¶ Wie wurden die KNN trainiert?
Das Training der KNN erfolgte durch überwachtes Lernen. Dabei wurden Brettzustände und Zielbewertungen (von einem Minimax-Algorithmus bereitgestellt, keine genauere Angabe zu Bewertungsfunktion im Paper von Thompson[4:4]) genutzt, um das Netzwerk zu trainieren:
-
Trainingsdaten:
- Eingaben: Kodierte Brettzustände gemäß der Darstellungen B oder C.
- Zielwerte: Bewertungen, die angeben, wie vorteilhaft ein Brettzustand für den aktuellen Spieler ist.
-
Trainingsprozess:
- Die Eingabedaten wurden vorwärts durch das Netzwerk propagiert, und die Ausgabe wurde mit den Zielwerten verglichen.
- Der Fehler wurde berechnet (mittels Mean Squared Error) und rückwärts durch das Netzwerk propagiert, um die Gewichte der Verbindungen zu aktualisieren.
-
Optimierung:
- Mithilfe eines Gradientenabstiegsverfahrens wurden die Gewichte angepasst.
- Eine Kombination aus Lernrate und Momentum stabilisierte den Lernprozess und erhöhte die Effizienz.
-
Überanpassung (Overfitting):
- Als potenzielles Problem wurde festgestellt, dass das Netzwerk bei zu kleinen Trainingsdaten oder zu langer Trainingsdauer spezifische Muster auswendig lernt, was die Generalisierungsfähigkeit beeinträchtigen kann.
¶ Erkenntnisse über die Anwendung auf Konane
¶ Effizienz und Leistung
- Nach dem Training konnten die KNN Brettzustände schneller bewerten als klassische Algorithmen wie Minimax oder Alpha-Beta-Pruning.
- Darstellung C bot die besten Ergebnisse, da sie die Brettinformationen präzise kodierte.
¶ Generalisation
- Das KNN zeigte eine gute Fähigkeit, auch unbekannte Brettzustände zu bewerten, sofern die Trainingsdaten repräsentativ waren.
¶ Vergleich mit klassischen Algorithmen
- Minimax und Alpha-Beta-Pruning: Diese Algorithmen waren präziser bei der Entscheidungsfindung, jedoch deutlich langsamer.
- KNN: Boten nach dem Training eine flexiblere und effizientere Alternative, besonders in Szenarien mit unbekannten Zuständen.
¶ Fazit
Die Integration von KNN in Konane zeigte, dass sie eine effektive und effiziente Methode zur Bewertung von Brettzuständen darstellen. Die Wahl der Brettdarstellung spielte eine entscheidende Rolle für die Leistungsfähigkeit des Netzwerks. Darstellung C war die erfolgreichste und zeigte die besten Ergebnisse bei der Verarbeitung von Brettinformationen.
¶ Referenzen
¶ Abbildungen
Abbildung 1: Konane Spielbrett: Screenshot von Cyningstan[2:2]
Abbildung 2: Spielbrett in Startaufstellung: Screenshot von Cyningstan[3:1]
Abbildung 3: Mögliche Spielzüge für den weißen Spieler: Screenshot von Cyningstan[2:3]
Abbildung 4: Utility Funktion: Screenshot aus Paper von Hendrick[5:6]
Abbildung 5: Minimax-Algorithmus: Screenshot aus Paper von Hendrick[5:7]
Abbildung 6: Alpha-Beta: Screenshot aus Paper von Hendrick[5:8]
Abbildung 7: Ergebnisse von Spielen gegen andere Agents: Screenshot aus Paper von Hendrick[5:9]
Abbildung 8: Ergebnisse zur Effizienz Ergebnisse. Übersetzt aus Paper von Hendrick[5:10] und Anpassung Dezimalkomma und Trennpunkte in deutsche Schreibweise
Abbildung 9: Künstliches Neuronales Netz: Screenshot aus Paper von Thompson[4:5]
¶ Textquellen
Seite „Kōnane“. In: Wikipedia – Die freie Enzyklopädie. Bearbeitungsstand: 20. Oktober 2023, 20:34 UTC. URL: https://de.wikipedia.org/w/index.php?title=Kōnane&oldid=238348848 (Abgerufen: 17. Januar 2025, 18:45 UTC) ↩︎
http://www.cyningstan.com/download/243/konane-leaflet ↩︎ ↩︎ ↩︎ ↩︎
Thompson, Darby. "Teaching a Neural Network to Play Konane." Undergraduate Thesis, Bryn Mawr College, Bryn Mawr PA (USA) (2005). ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Hendrick, Kaitlin. "Analysis of Artificial Intelligence Techniques for Konane." (2018). ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎